







说明
教程借鉴厚国兄项目进行简化
地址 https://gitee.com/zhuxiaohuaqn/esp32s3-ai-chat
物料准备
- ESP32-S3-N16R8开发板
- microSD卡(不大于32GB)
- 读卡器
- microSD 卡模块
- INMP441音频模块
接线
INMP441
| INMP441 | ESP32-S3 |
|---|---|
| SCK(BCLK) | GPIO4 |
| WS(LRC) | GPIO5 |
| SD(DIN) | GPIO6 |
| VCC | 3V3 |
| GND | GND |
microSD SPI
| microSD | ESP32-S3 |
|---|---|
| CS | GPIO10 |
| MISO | GPIO13 |
| MOSI | GPIO11 |
| SCK | GPIO12 |
| VCC | 5V |
| GND | GND |
固件输入
录音固件
刷入固件的方式有很多,我就不再过多赘述
录制完数据大概是这样

采集唤醒词音频
接好线后,连接开发板到电脑,打开串口工具,这里以arduino ide为例,这里的标签名称随便起,比如我的就起名 fulai,然后回车发送
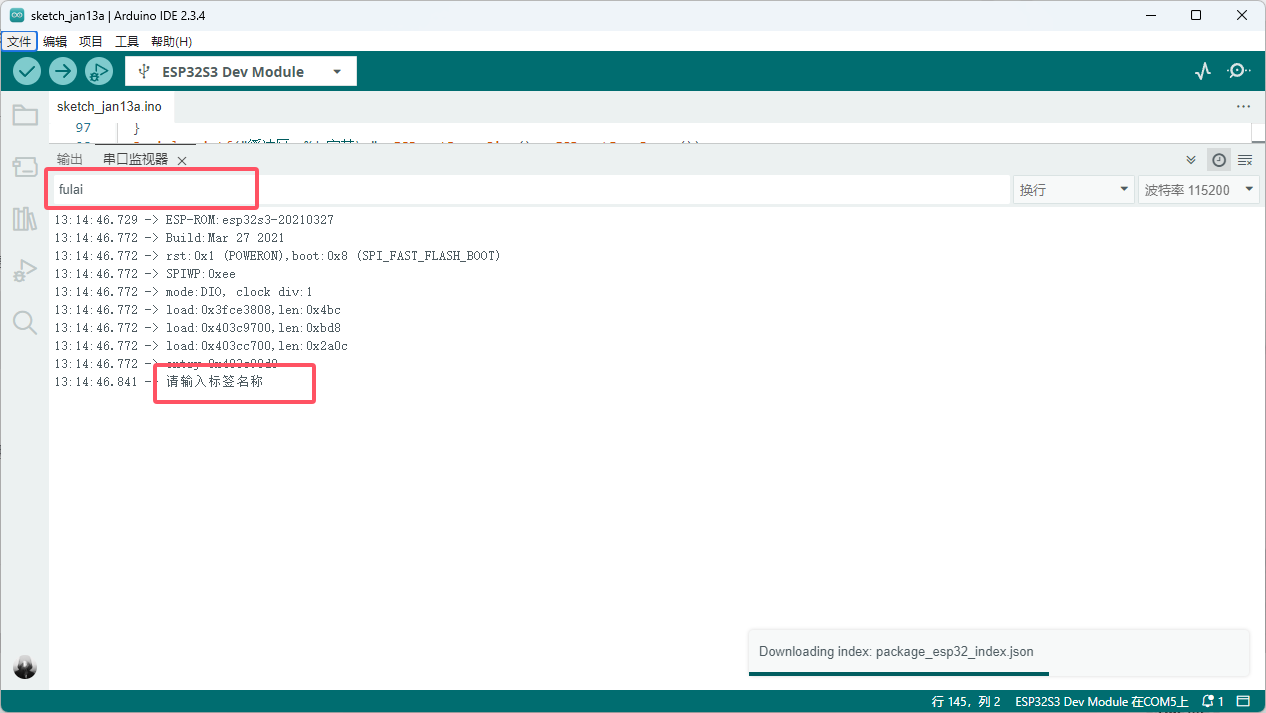
提示输入rec录制,此时会开启一个十秒录制,在十秒内重复录制唤醒词,比如 福来 ,(录制10组以上)
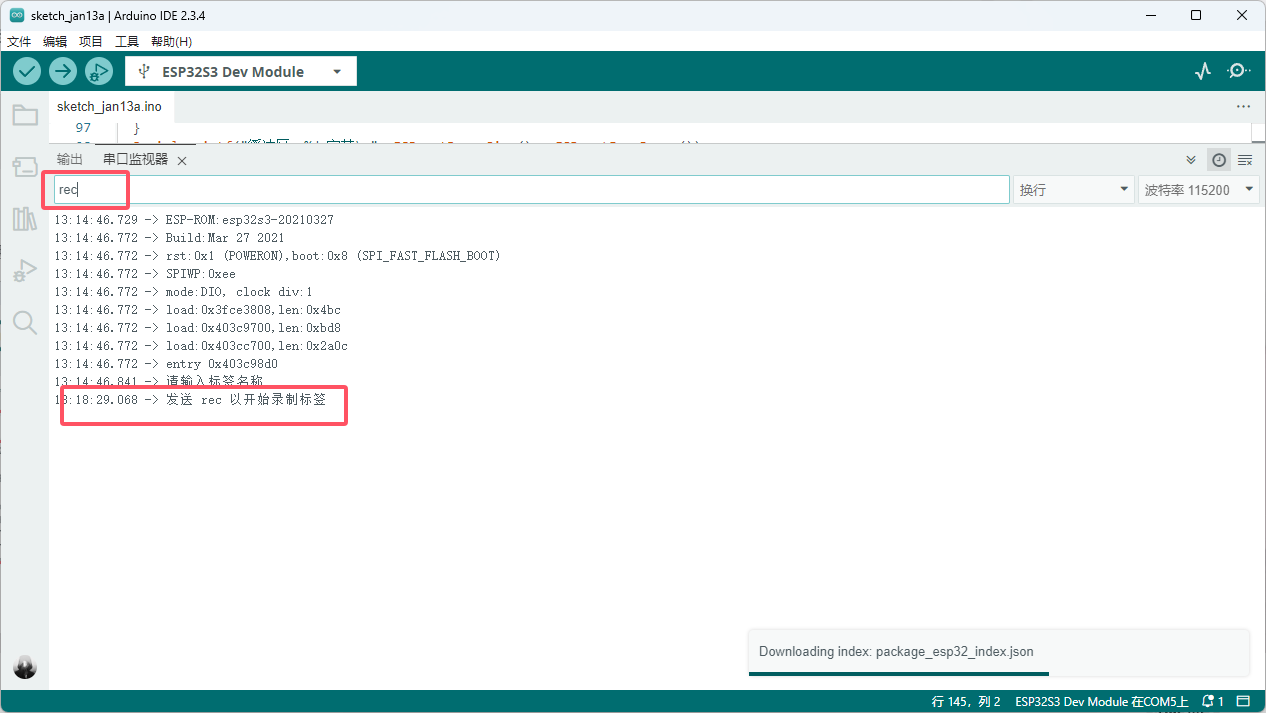
采集非唤醒词
非唤醒词标签一般为noise 就如这样,所谓非唤醒词就是随便说的话,比如你可以读文章,读小说(录制10组以上)
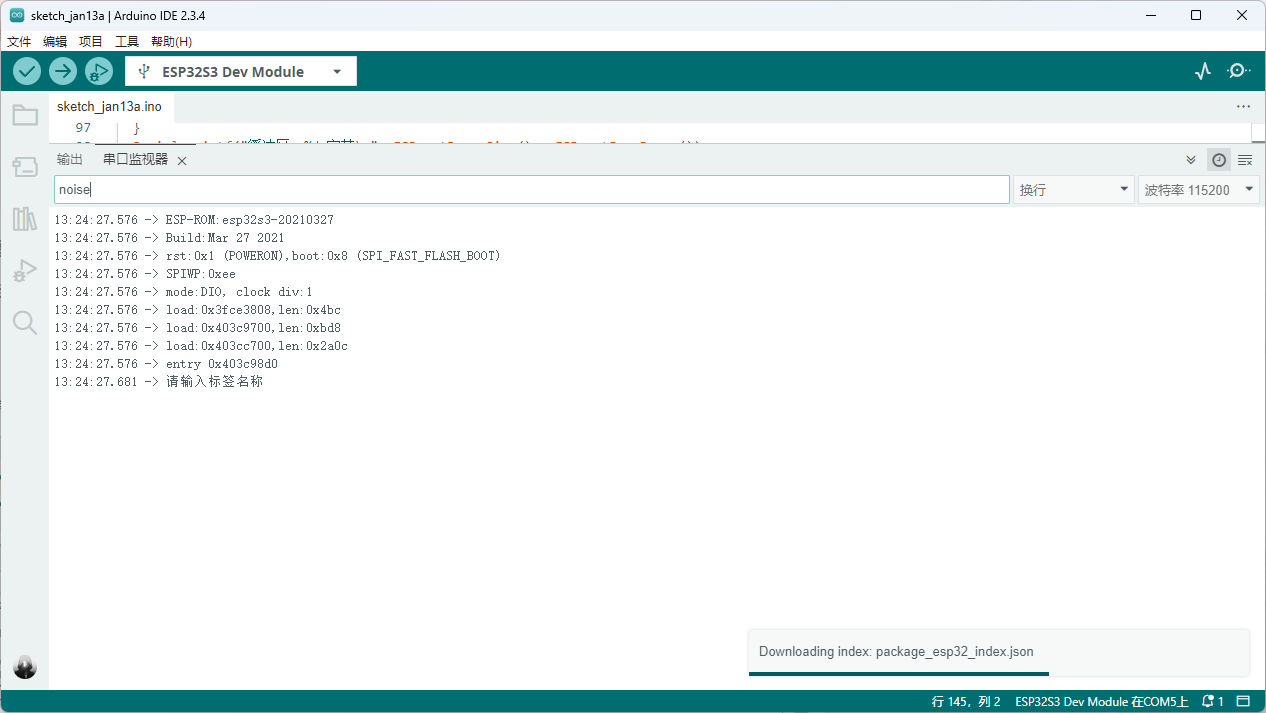
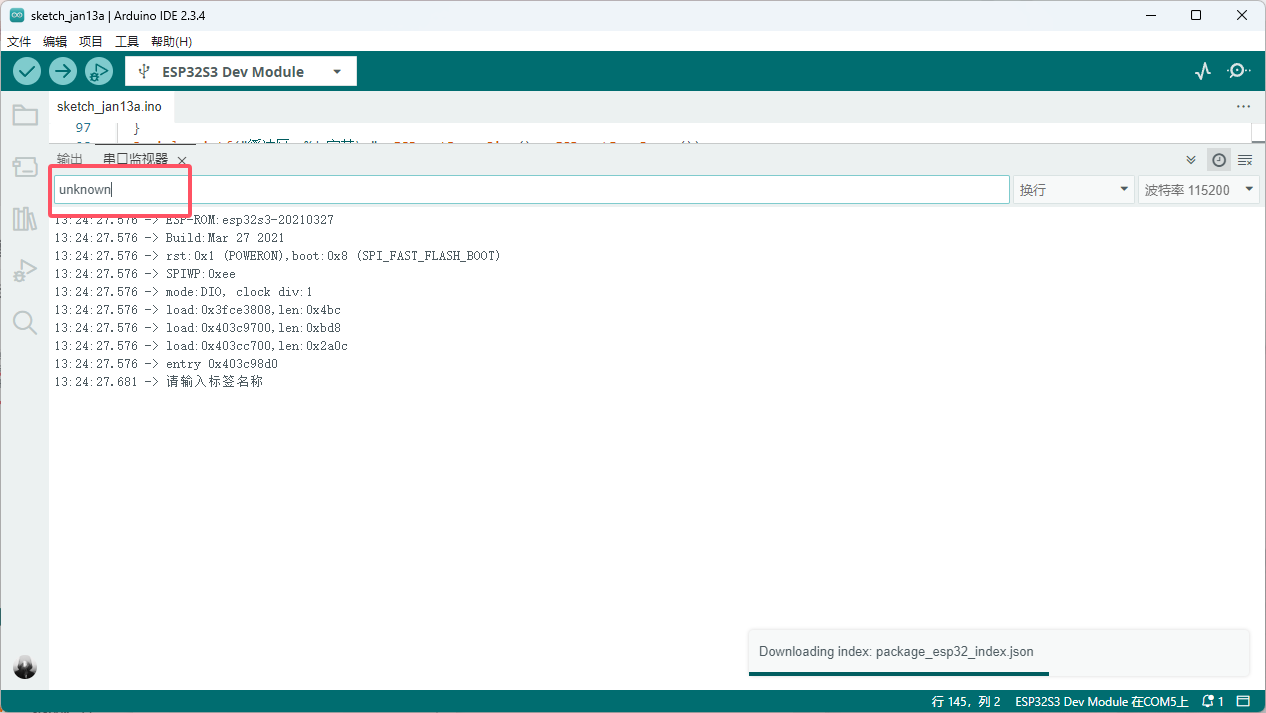
采集静默音频
静默音频标签一般为unknown ,静默顾名思义就是什么都不说,(录制10组以上)
训练模型
Edge Impulse注册账号
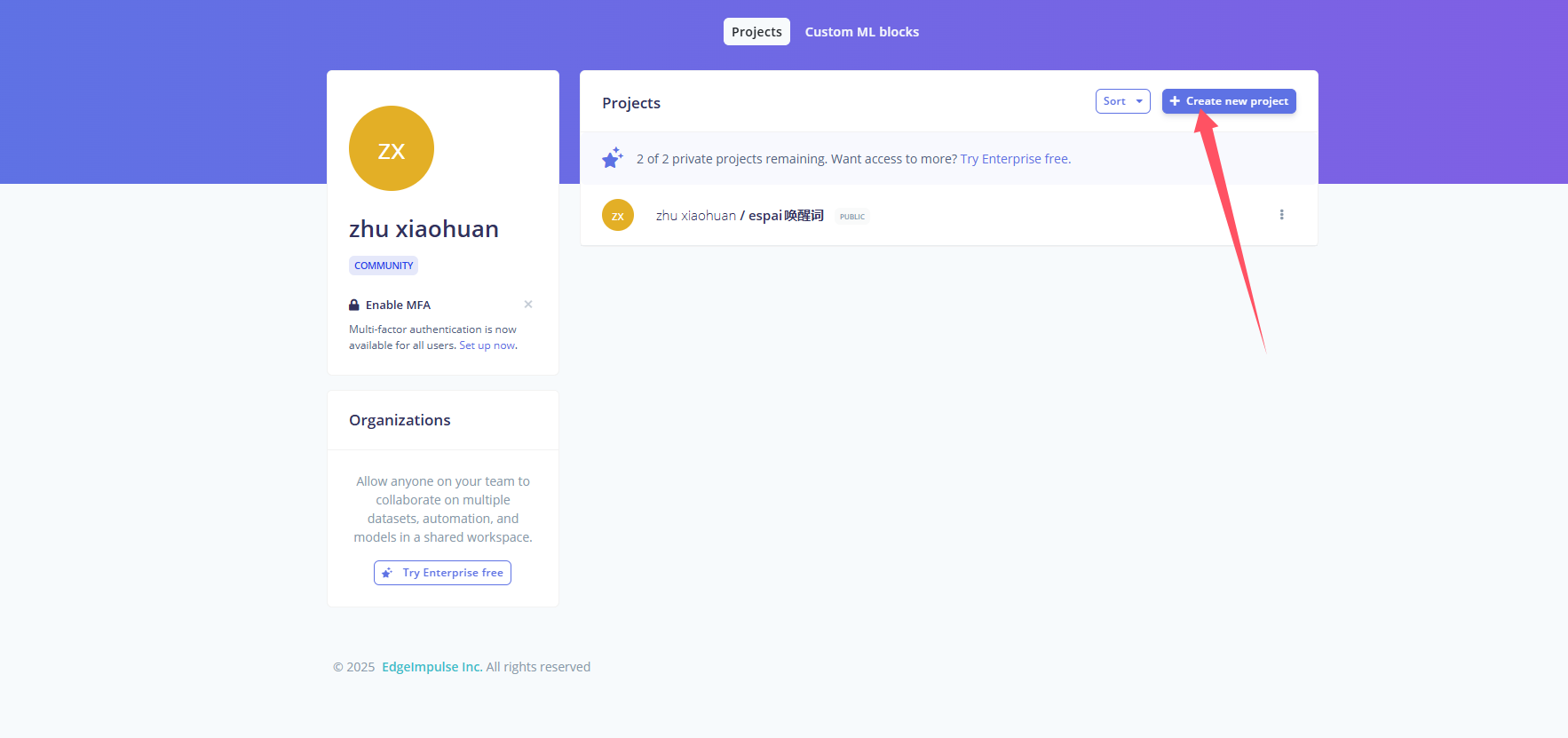
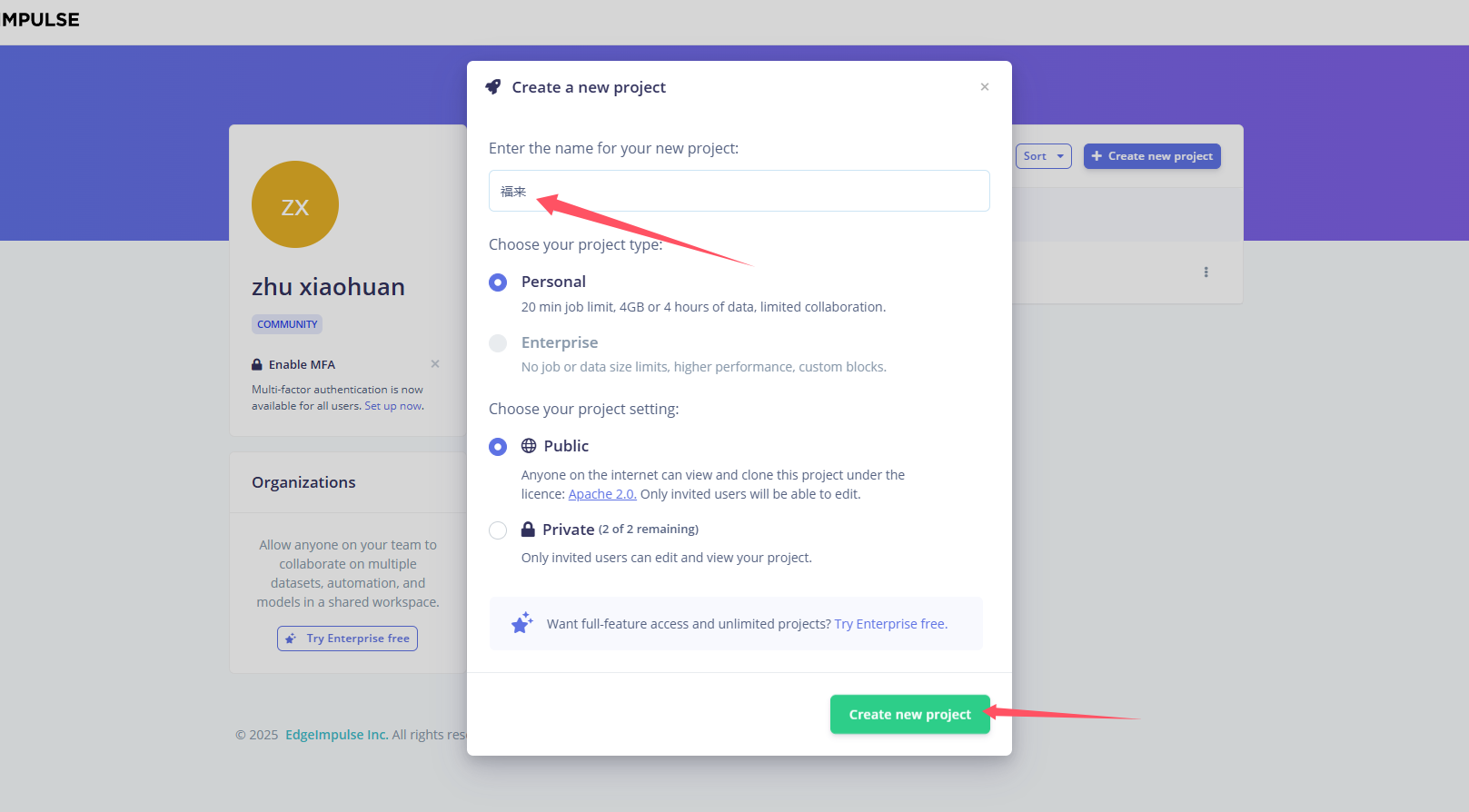
创建项目
https://studio.edgeimpulse.com/studio/profile/projects
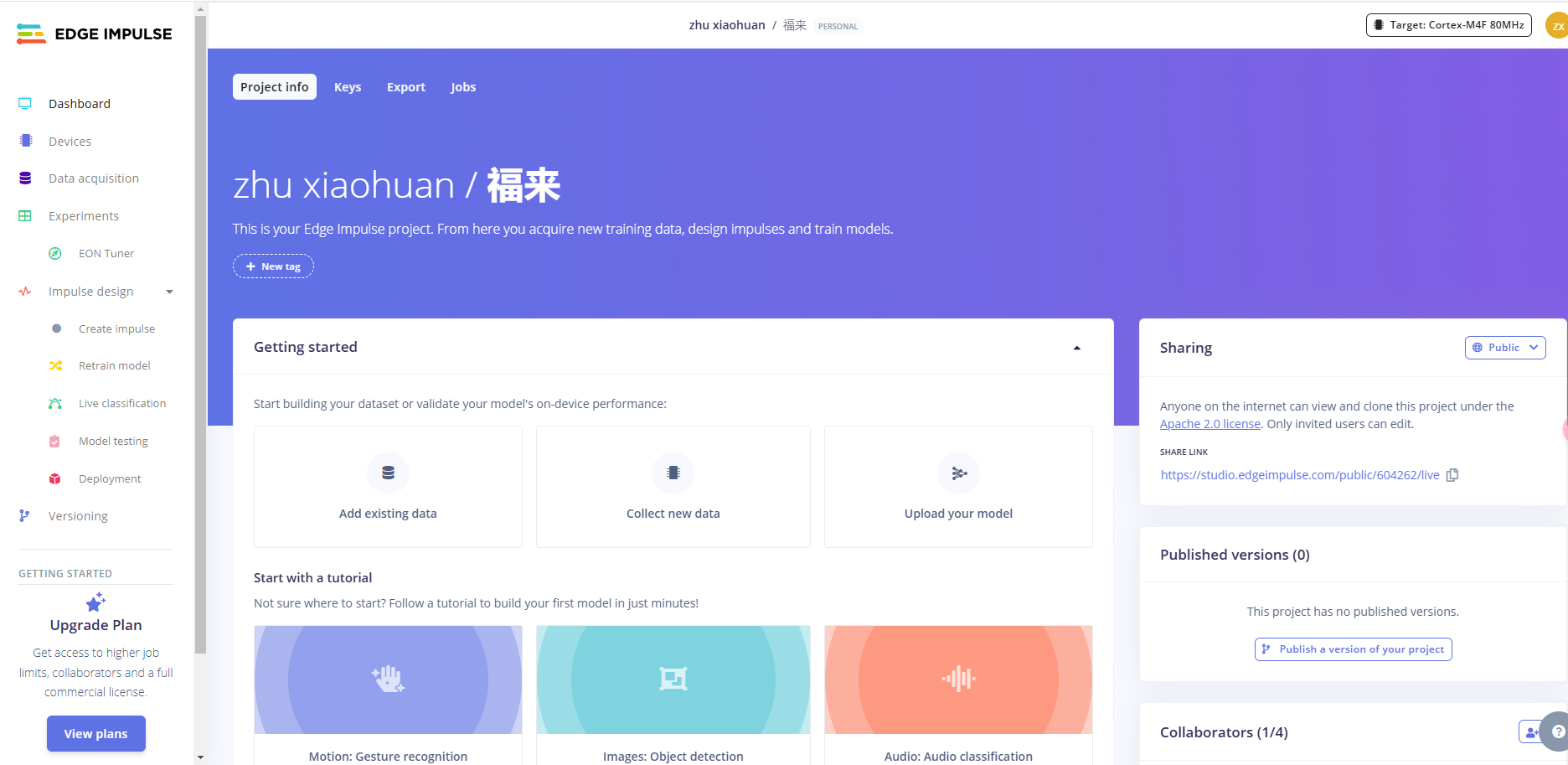
会自动跳转到这里
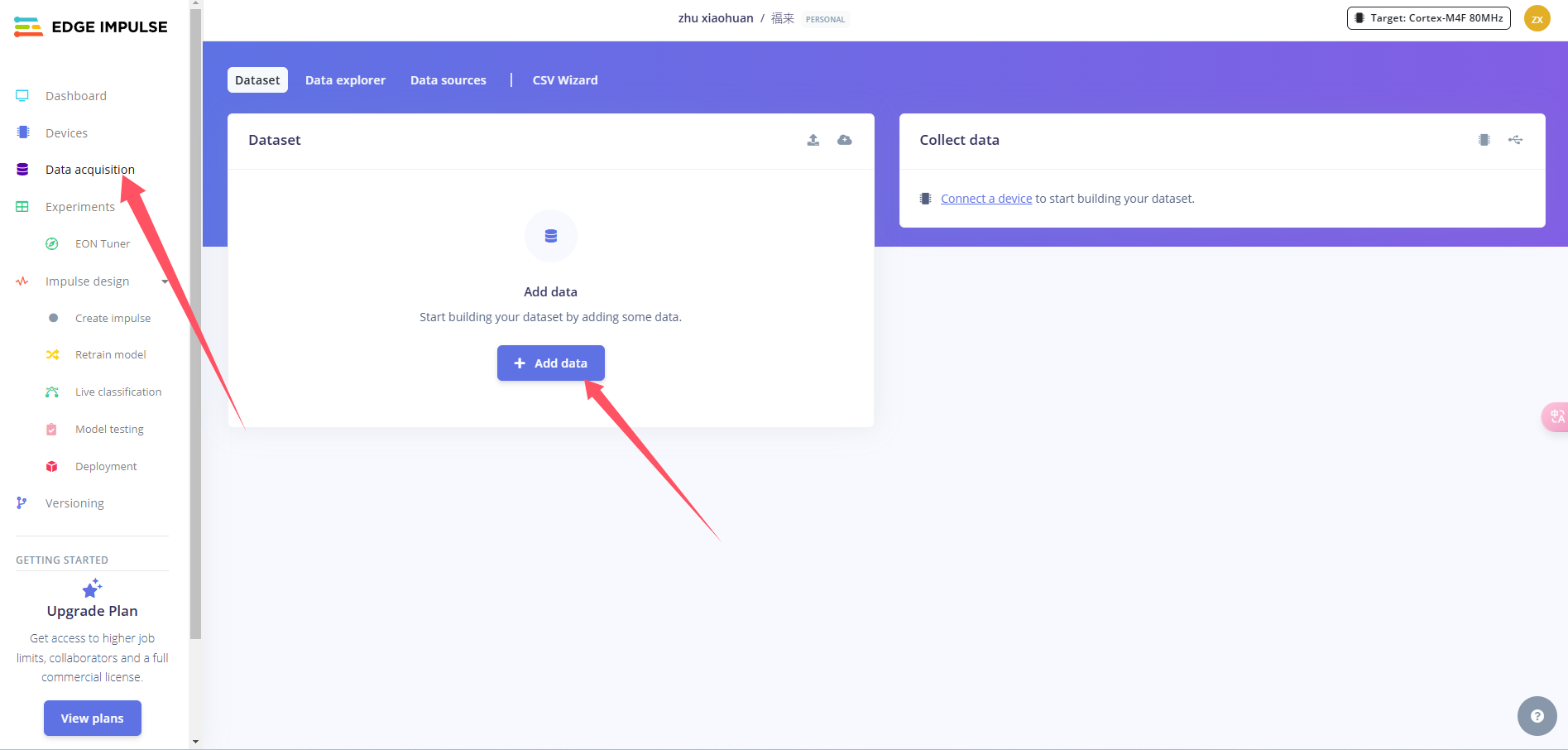
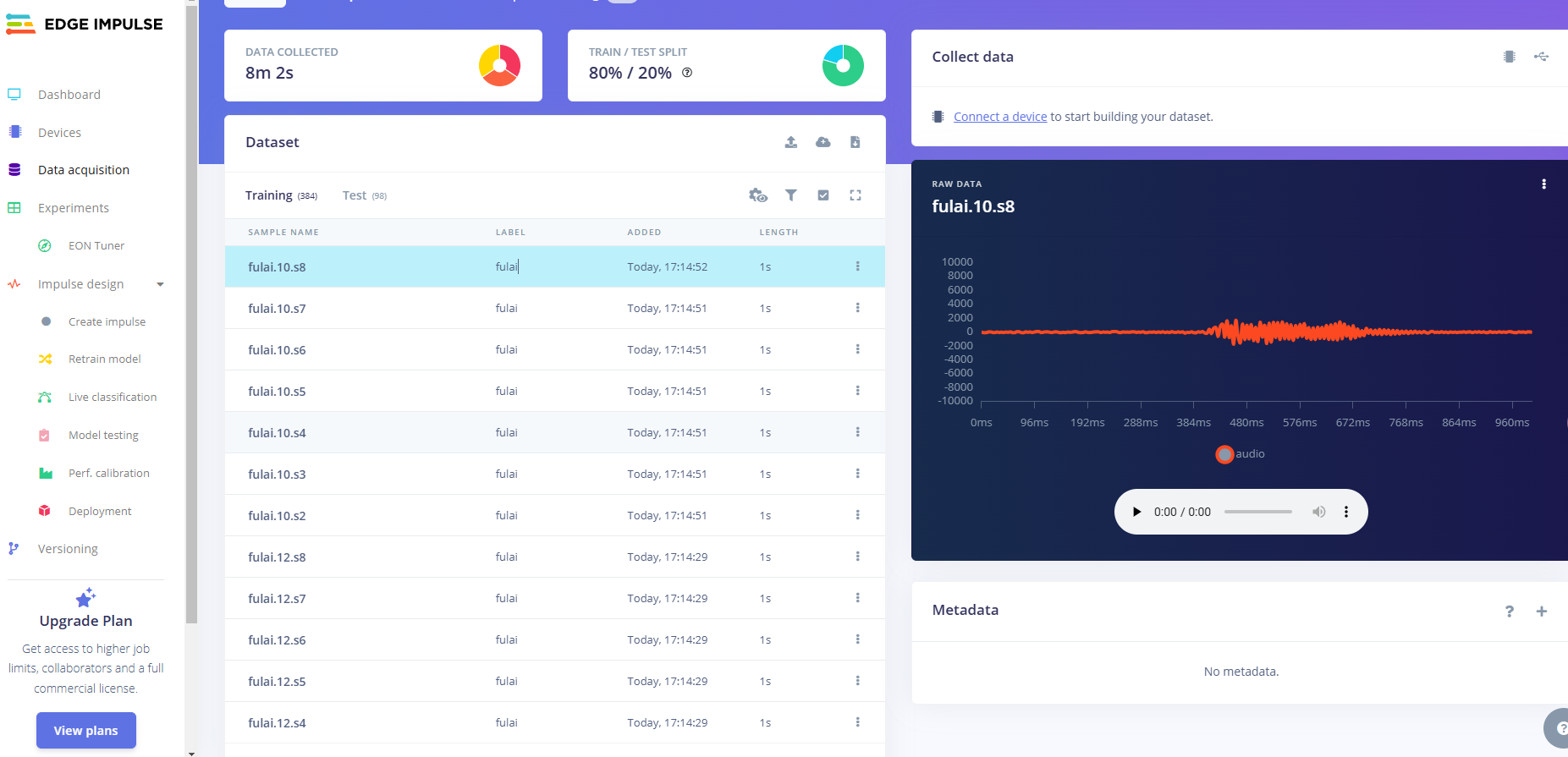
上传训练文件
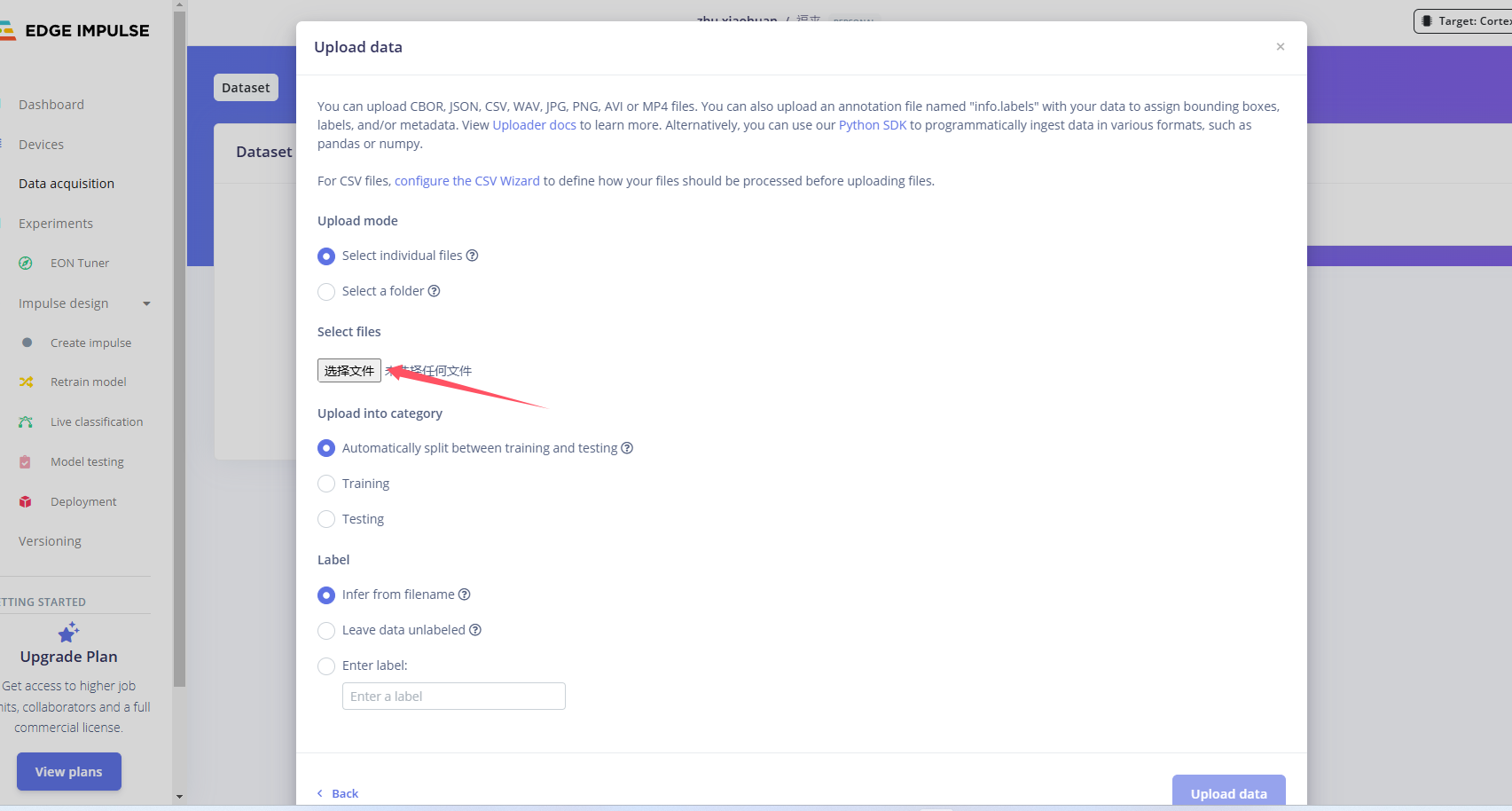
创建项目后,在Data Acquisition部分选择Upload Existing Data工具。选择要上传的文件
选择音频文件所在目录
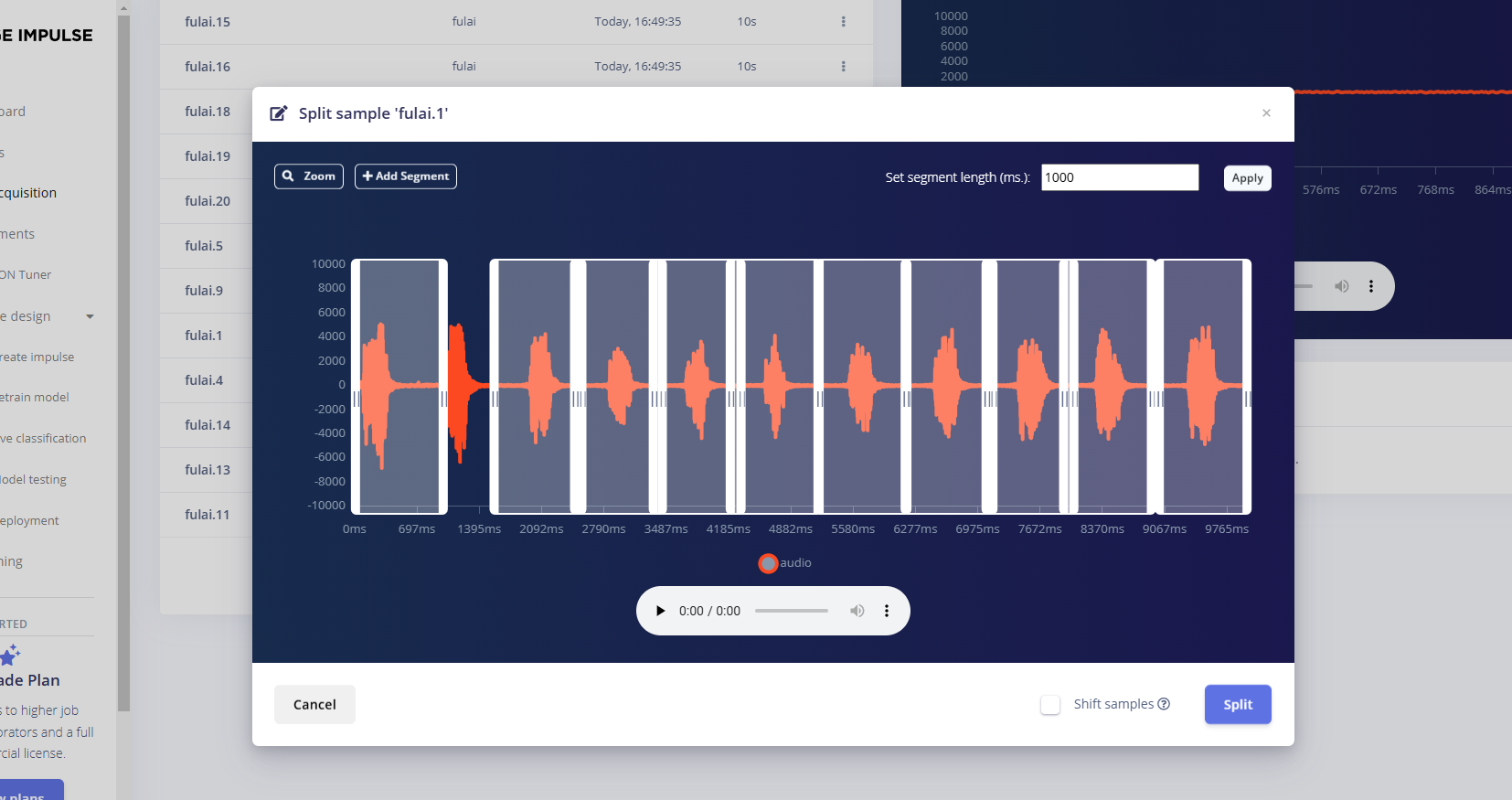
分割音频
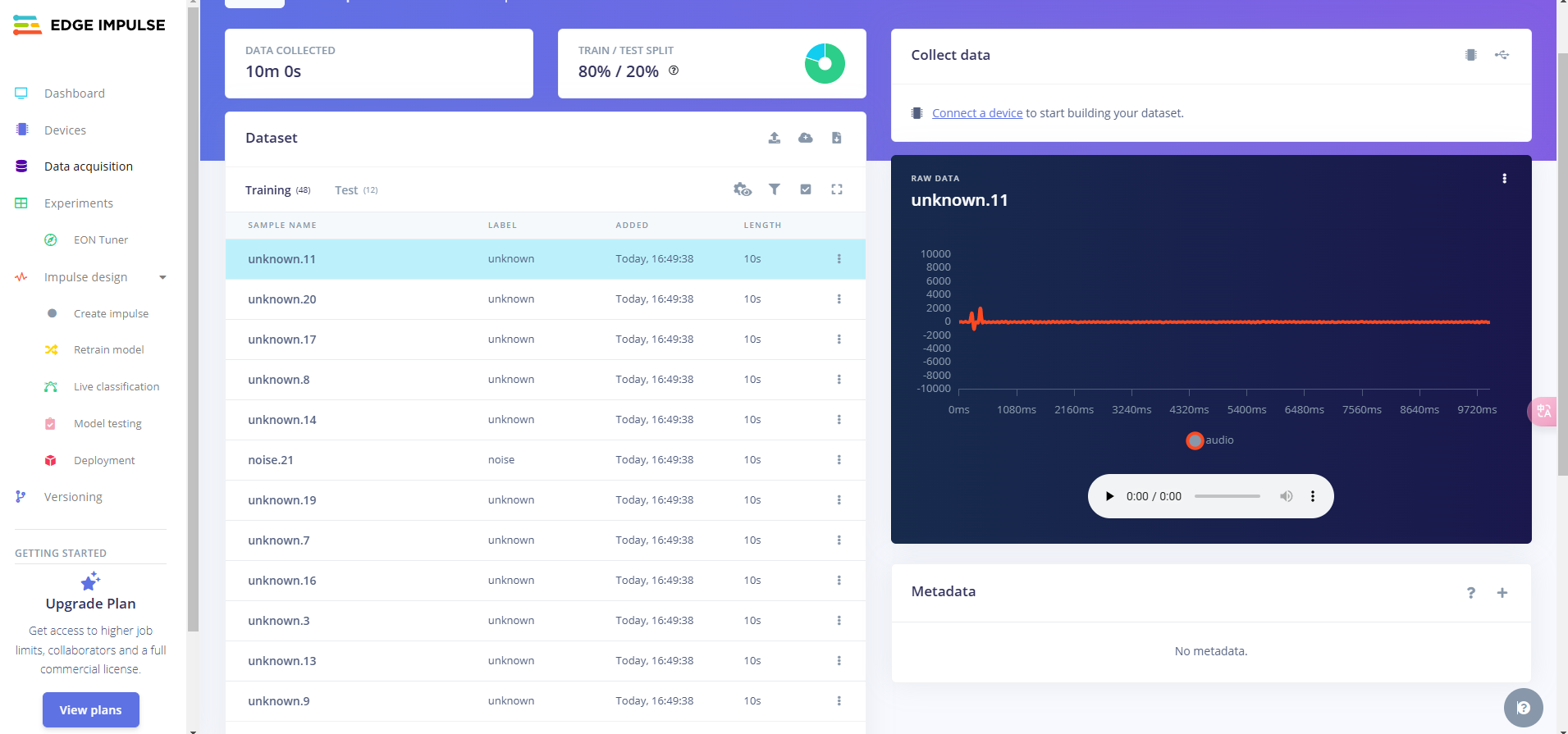
我们需要将上传的数据分割成1秒,现在上传的数据是10秒
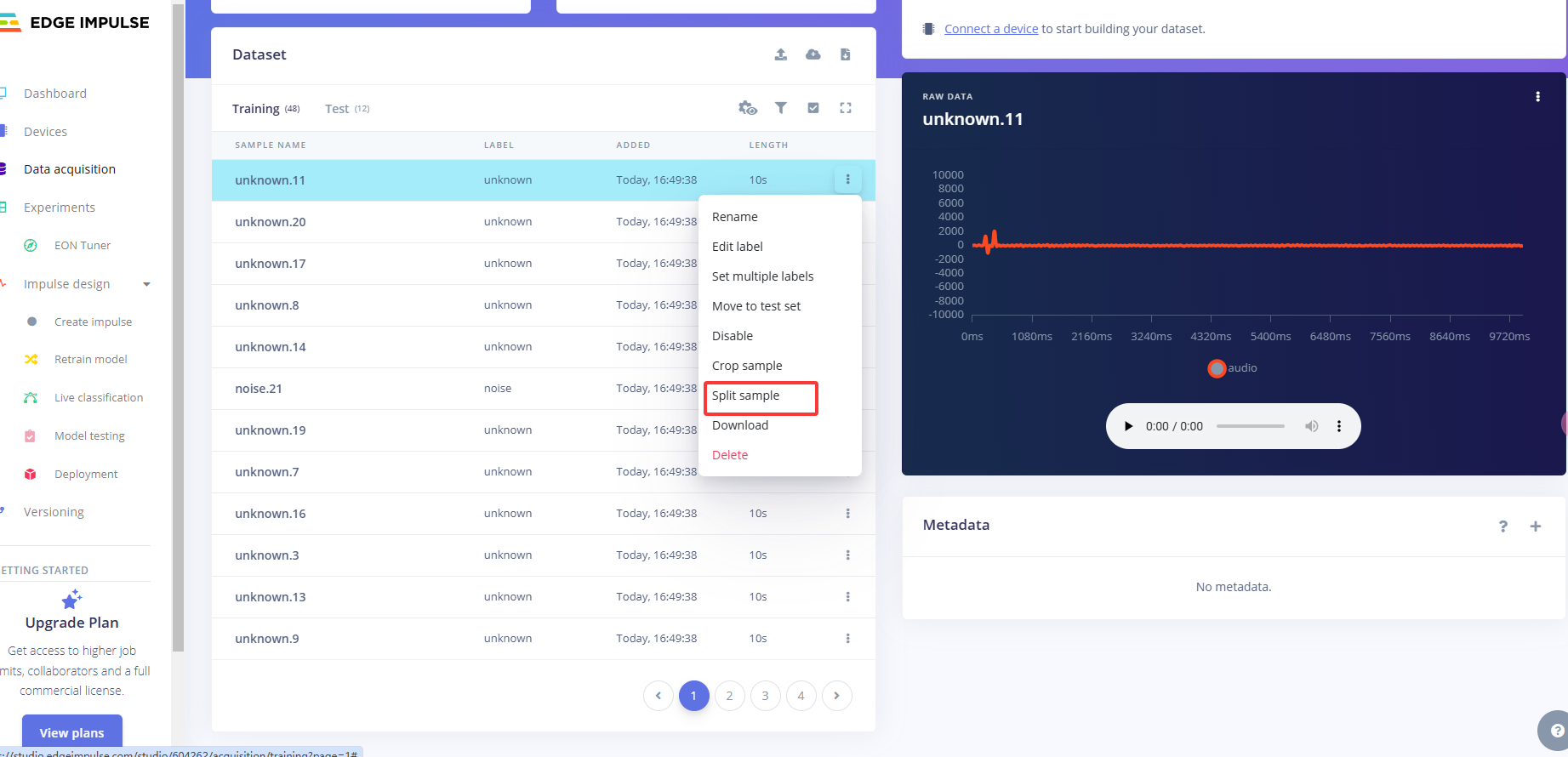
点击样本名称后的三个点,并选择Split sample
每个框代表1秒,可以选择add添加框,Split保存
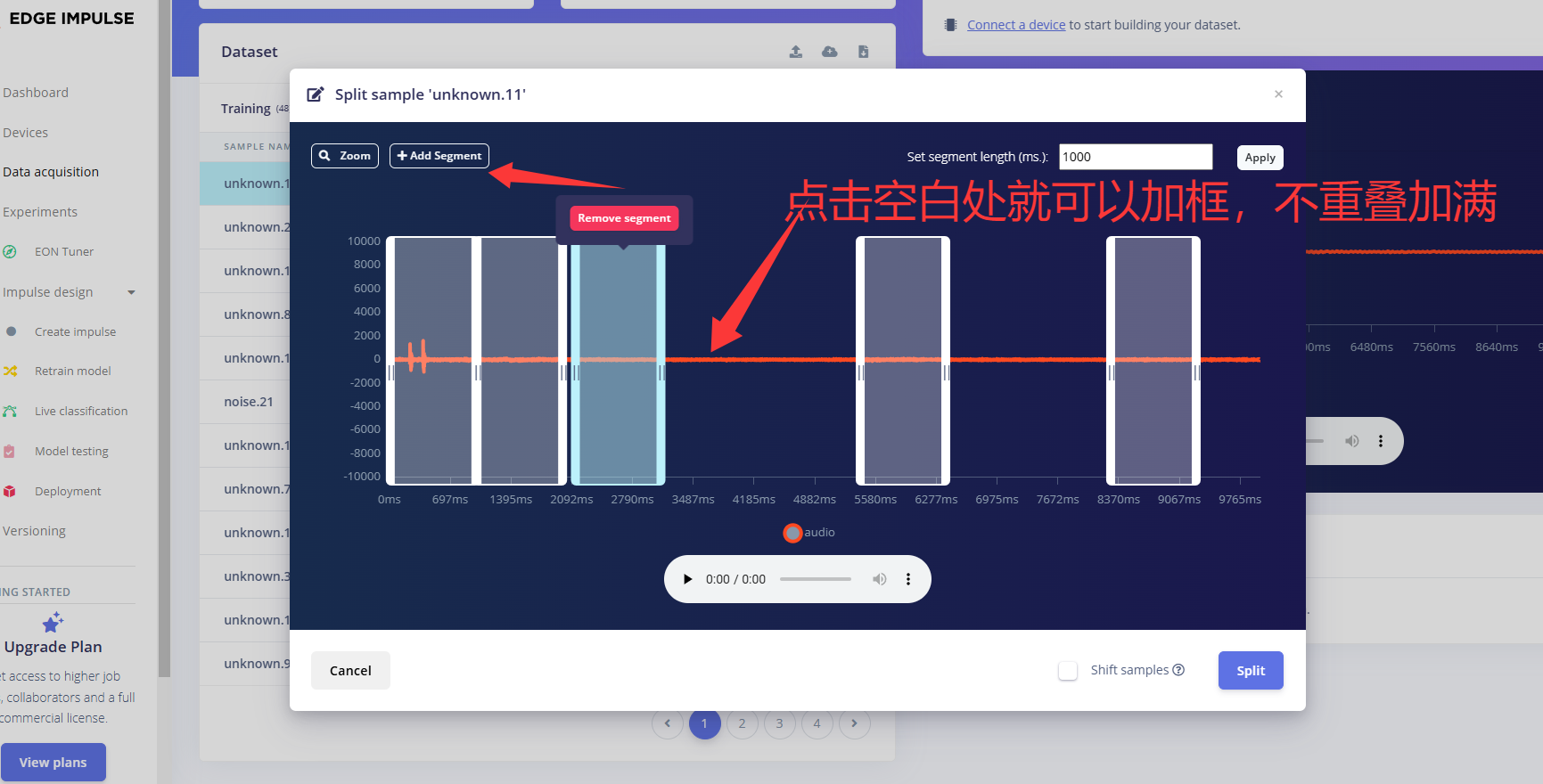
唤醒词就只框起伏的地方
静默样本只框声音部分
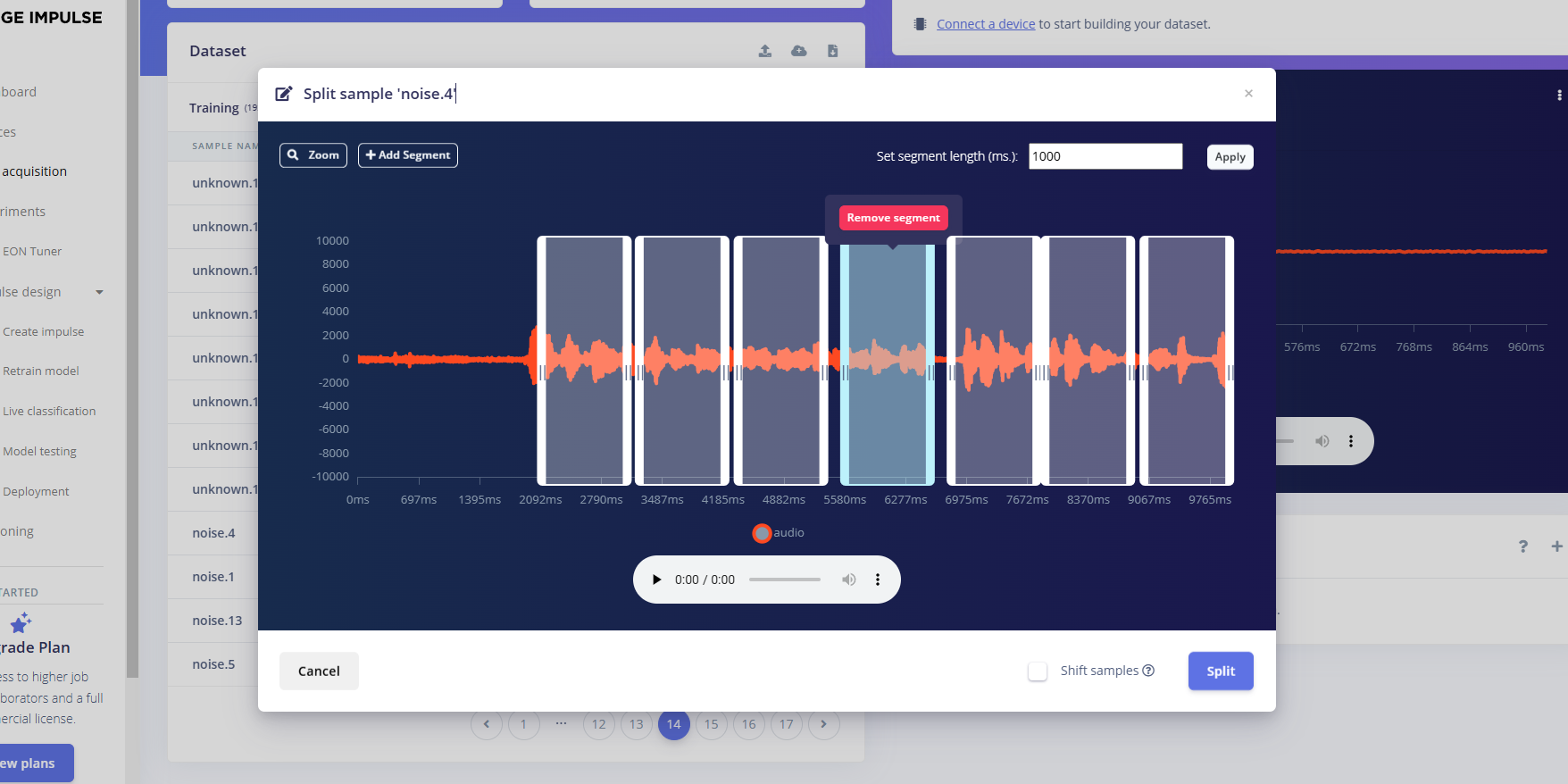
分割完成全是1秒的音频
创造脉冲信号
点击左侧Create impulse,然后点击Add a processing block添加Audio(MFCC),使用MFCC,它使用梅尔频率倒谱系数从音频信号中提取特征,这对人类声音非常有用。
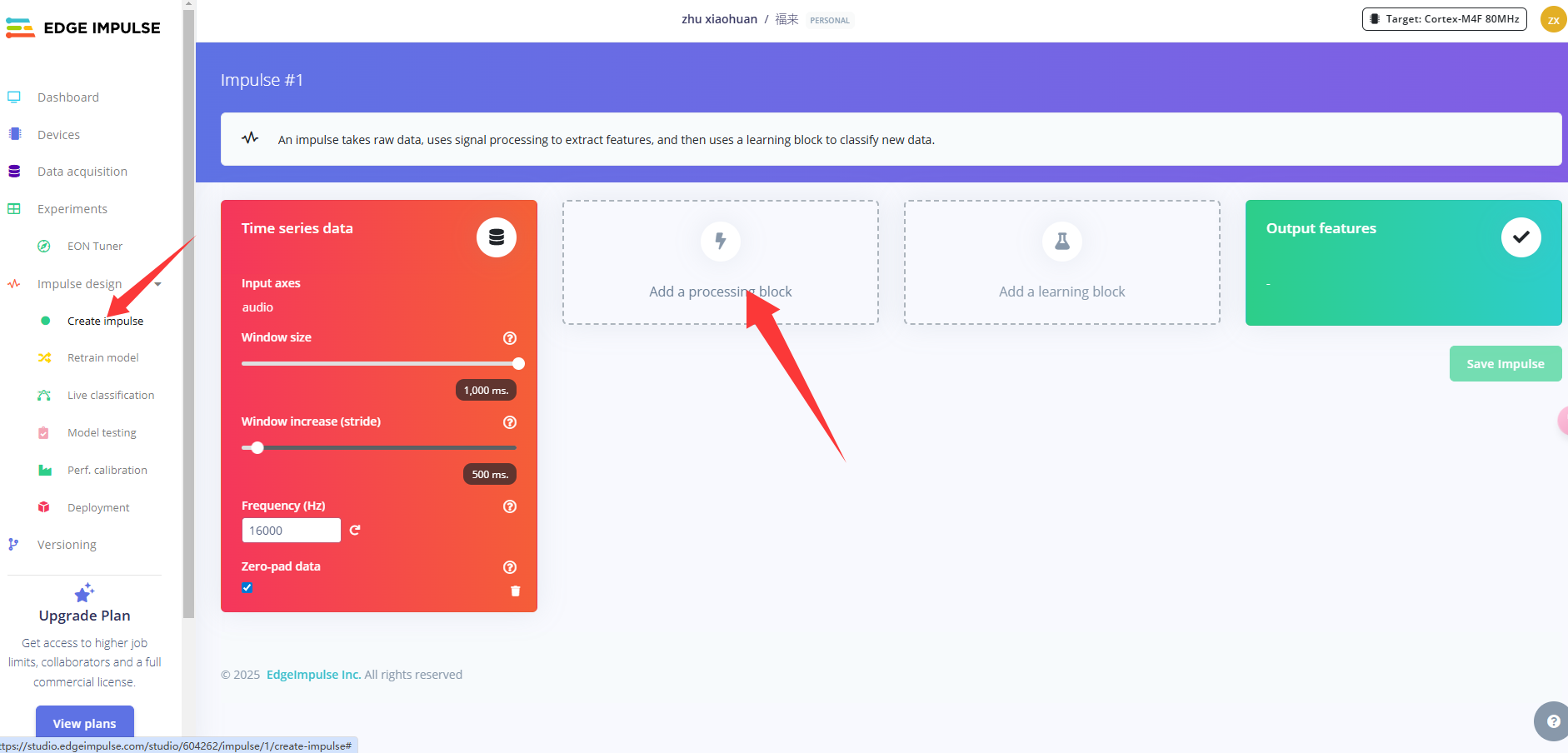
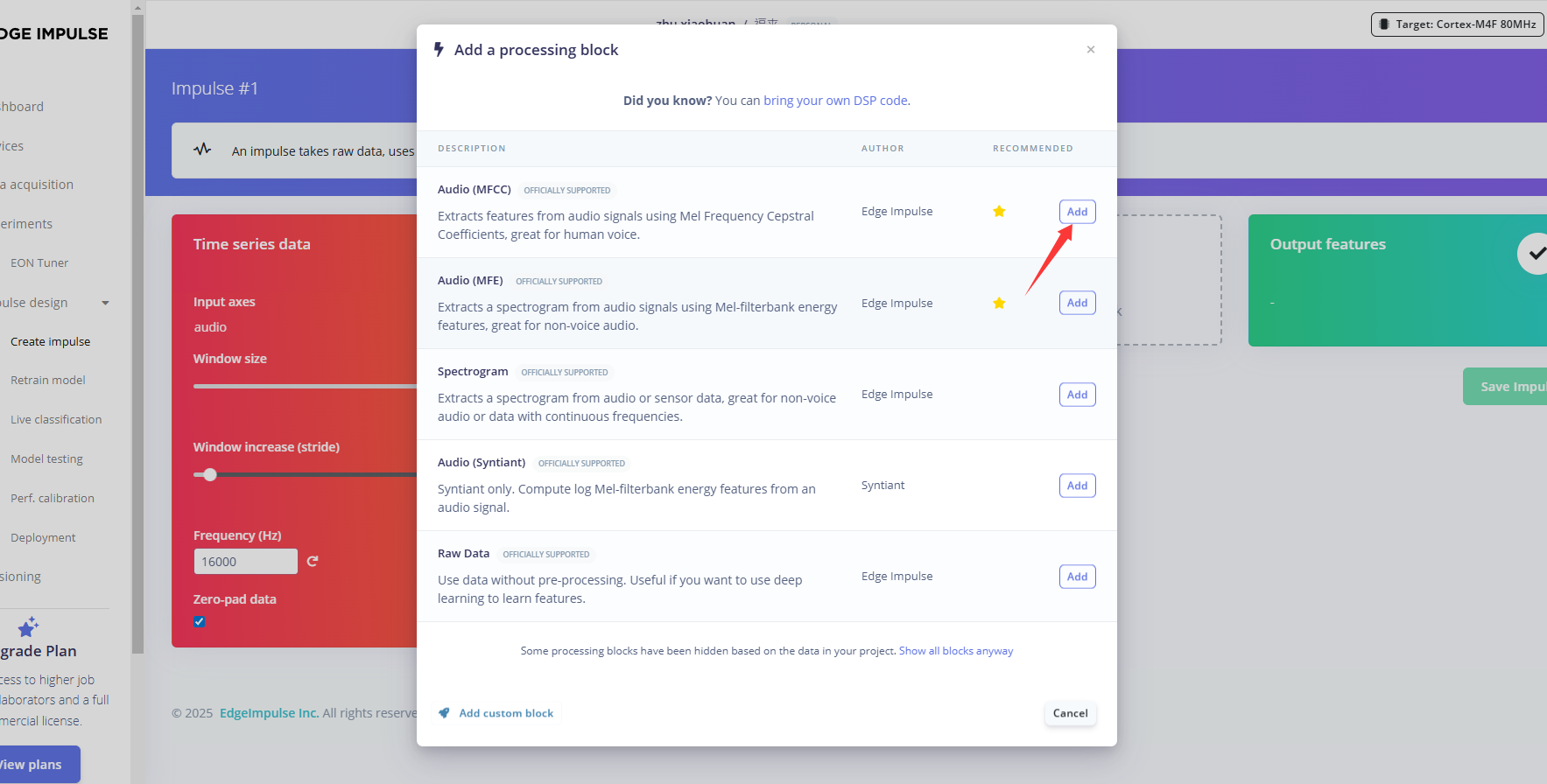
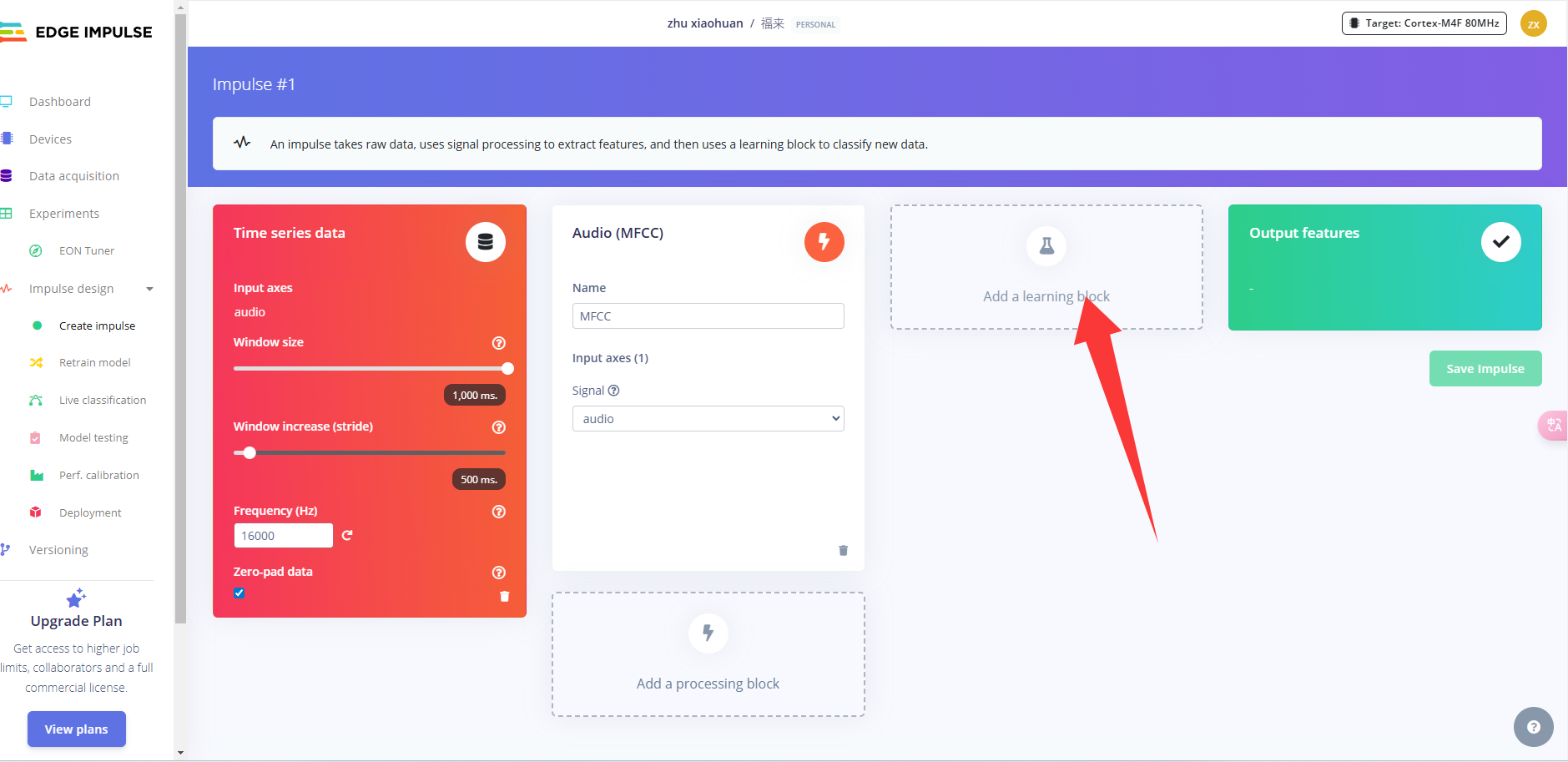
预处理(MFCC)
下一步是创建下一阶段要训练的图像。
点击MFCC,我们可以保留默认参数值,直接点击Save parameters。
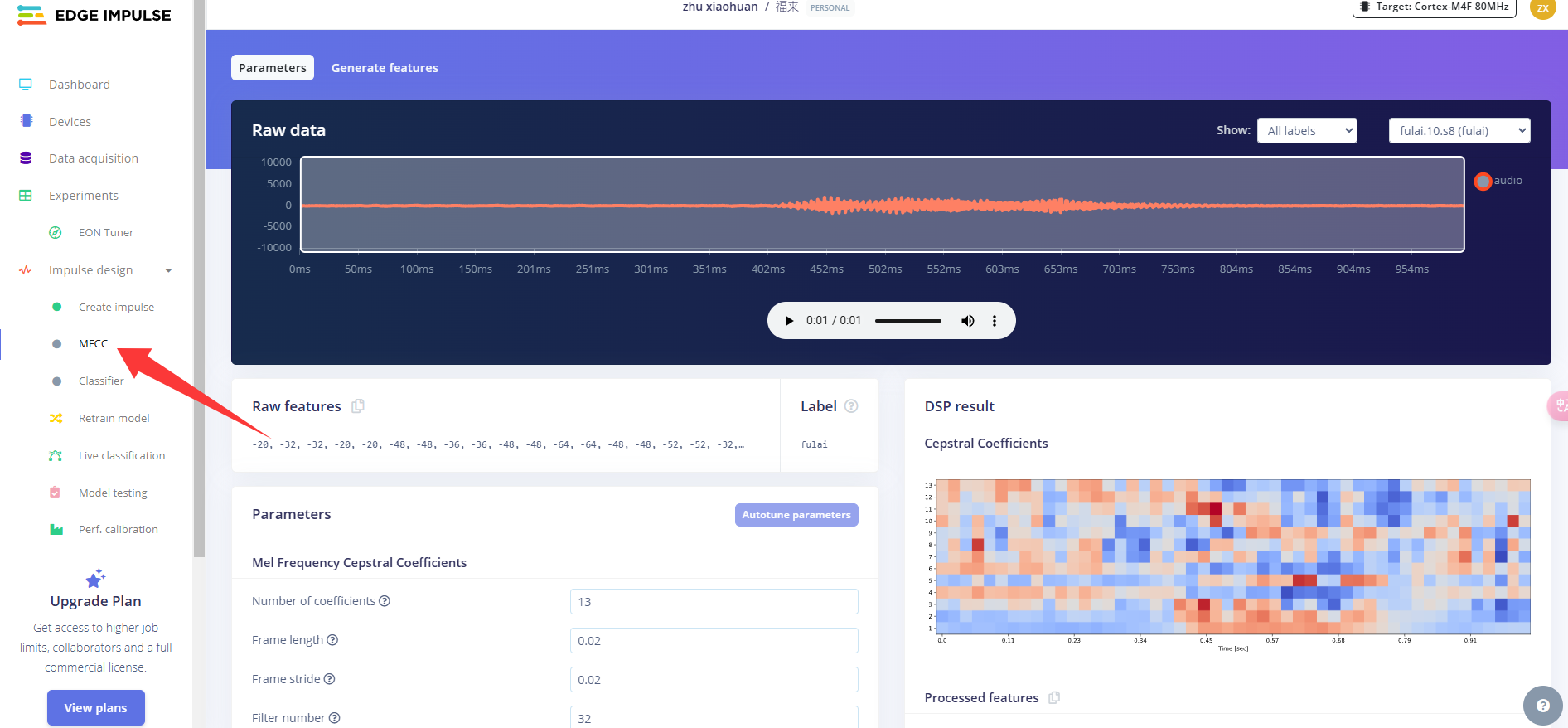
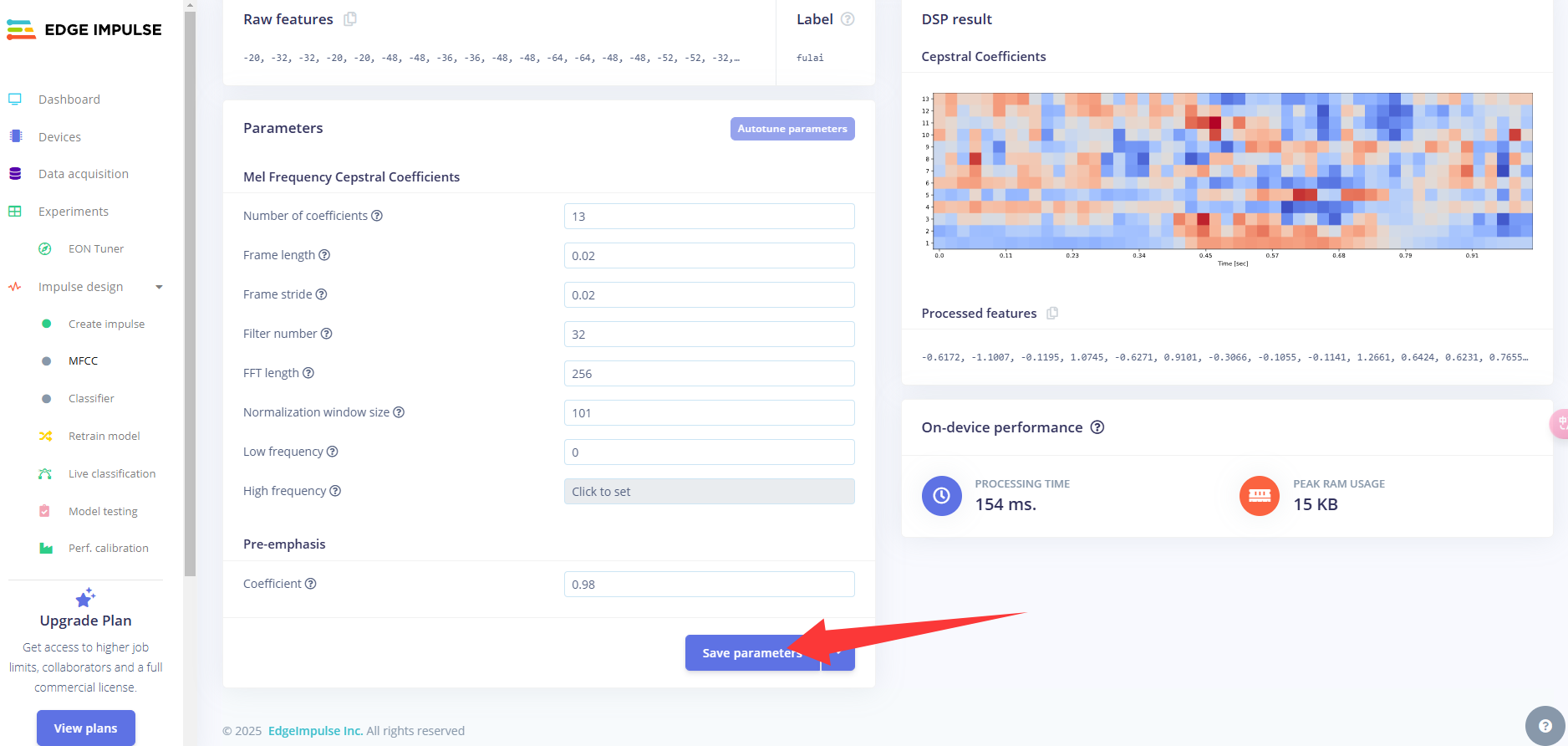
点击Generate features,生成3个标签数据的特征。这里需要稍等一会
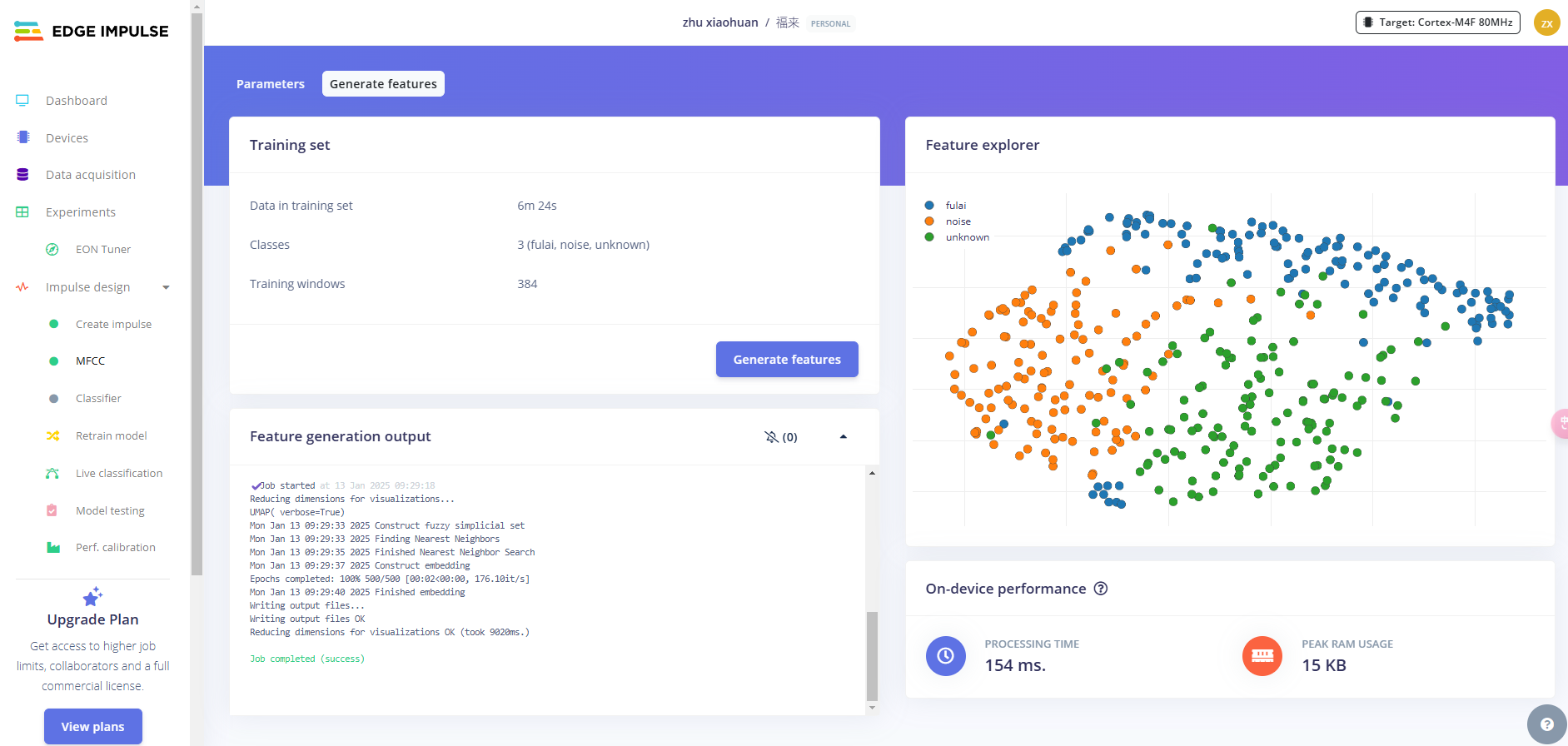
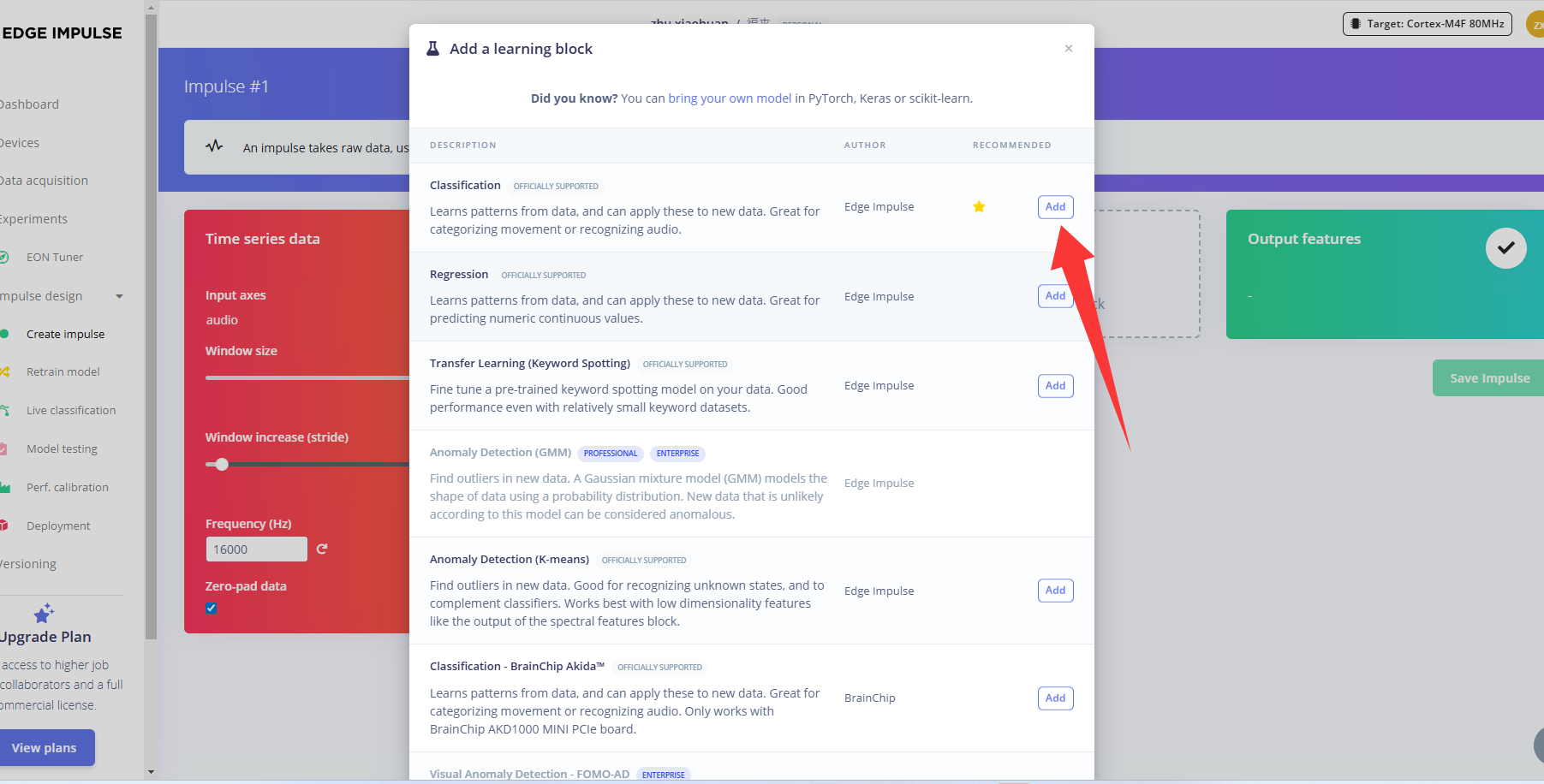
模型设计与训练(Classifier)
接着,我们需要对模型的结构进行设计和开始训练,步骤如下:
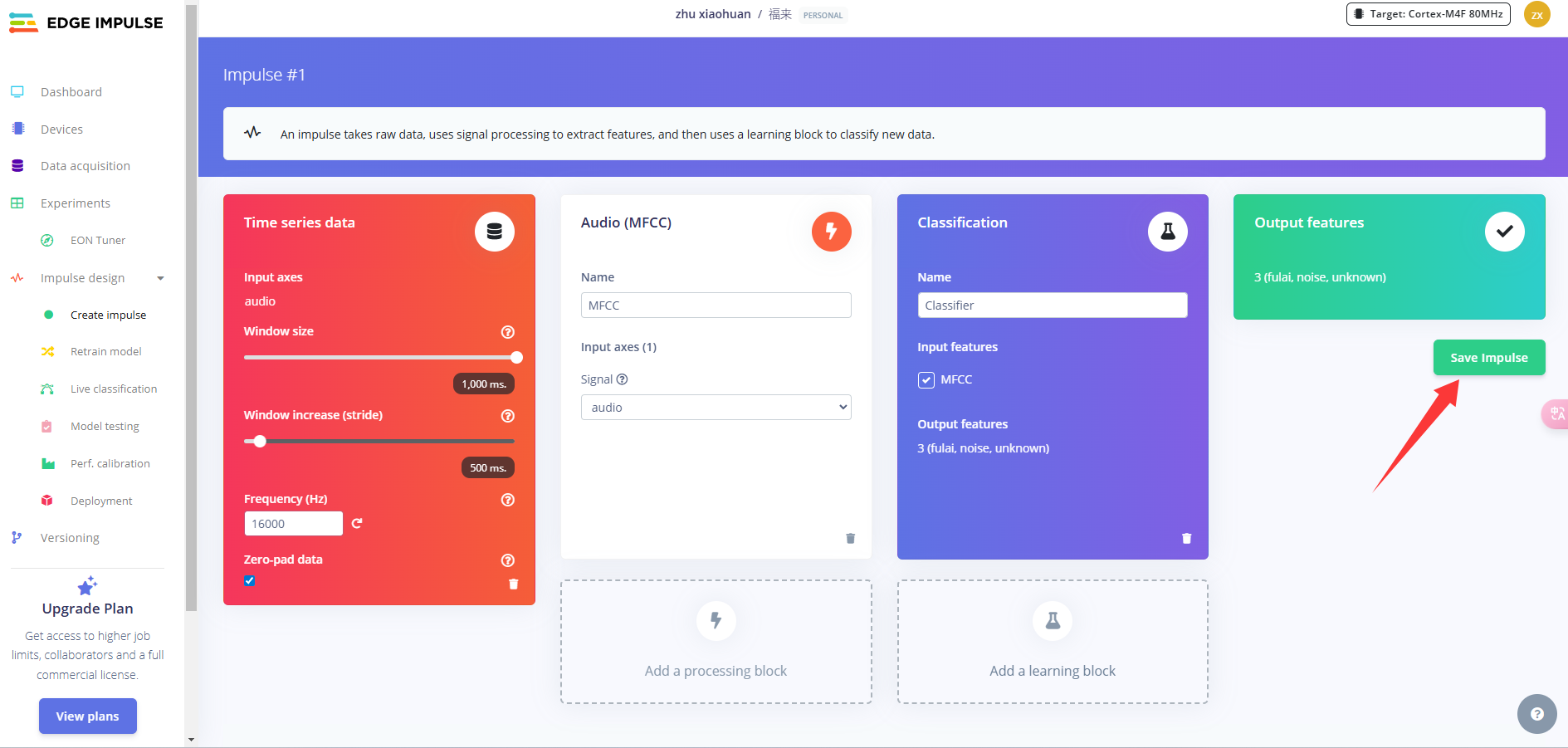
点击左侧 Classifier,整个模型的结构设计已经配置好,然后点击 save&train,开始训练模型。
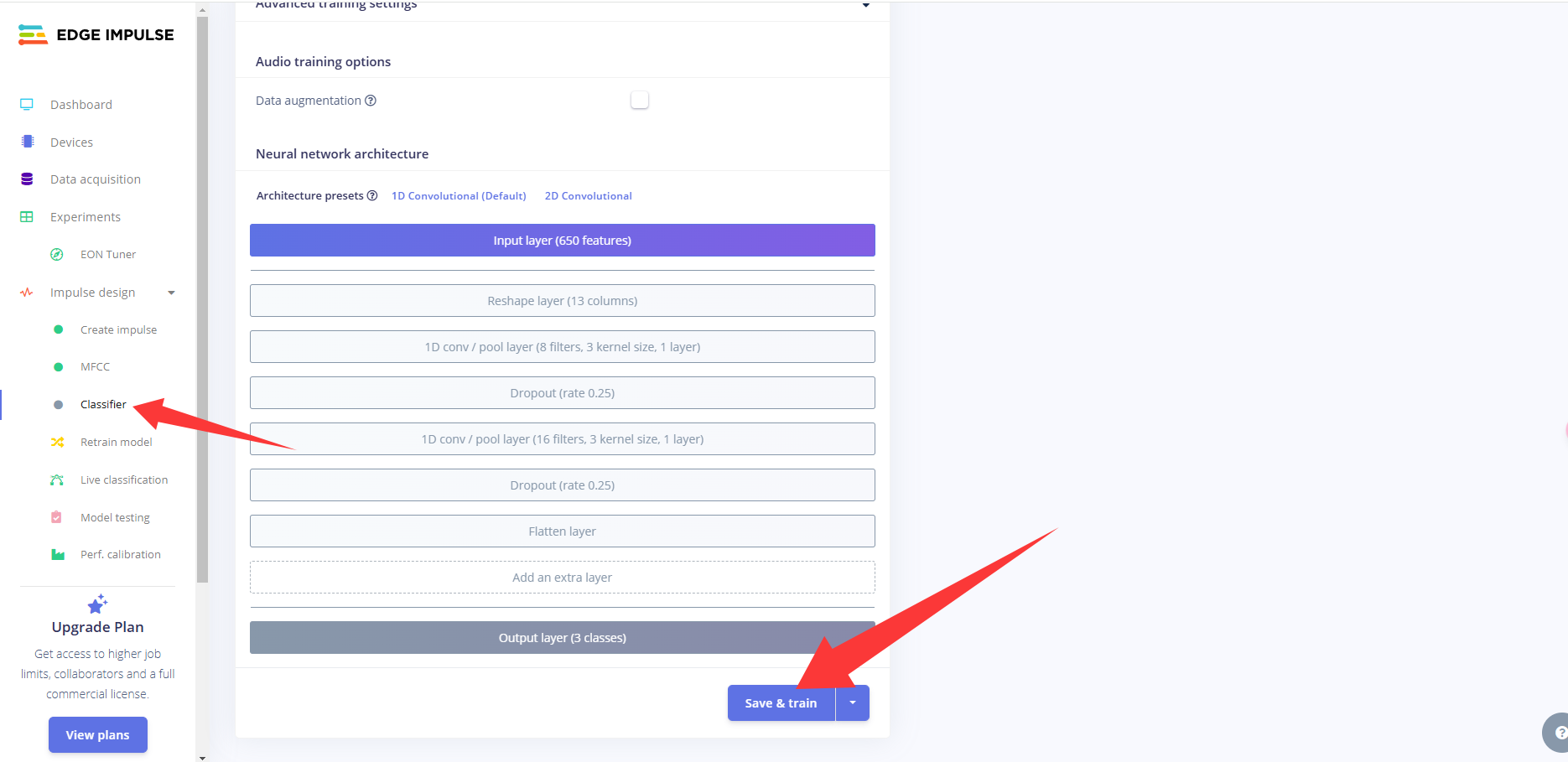
稍等一会,会出训练结果
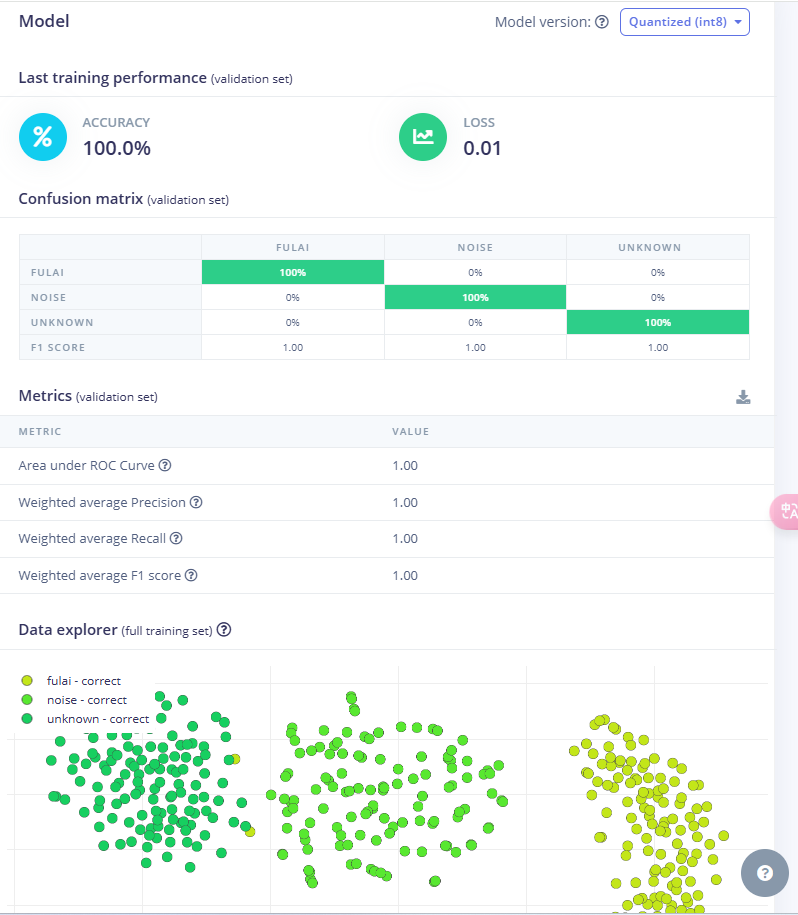
模型测试
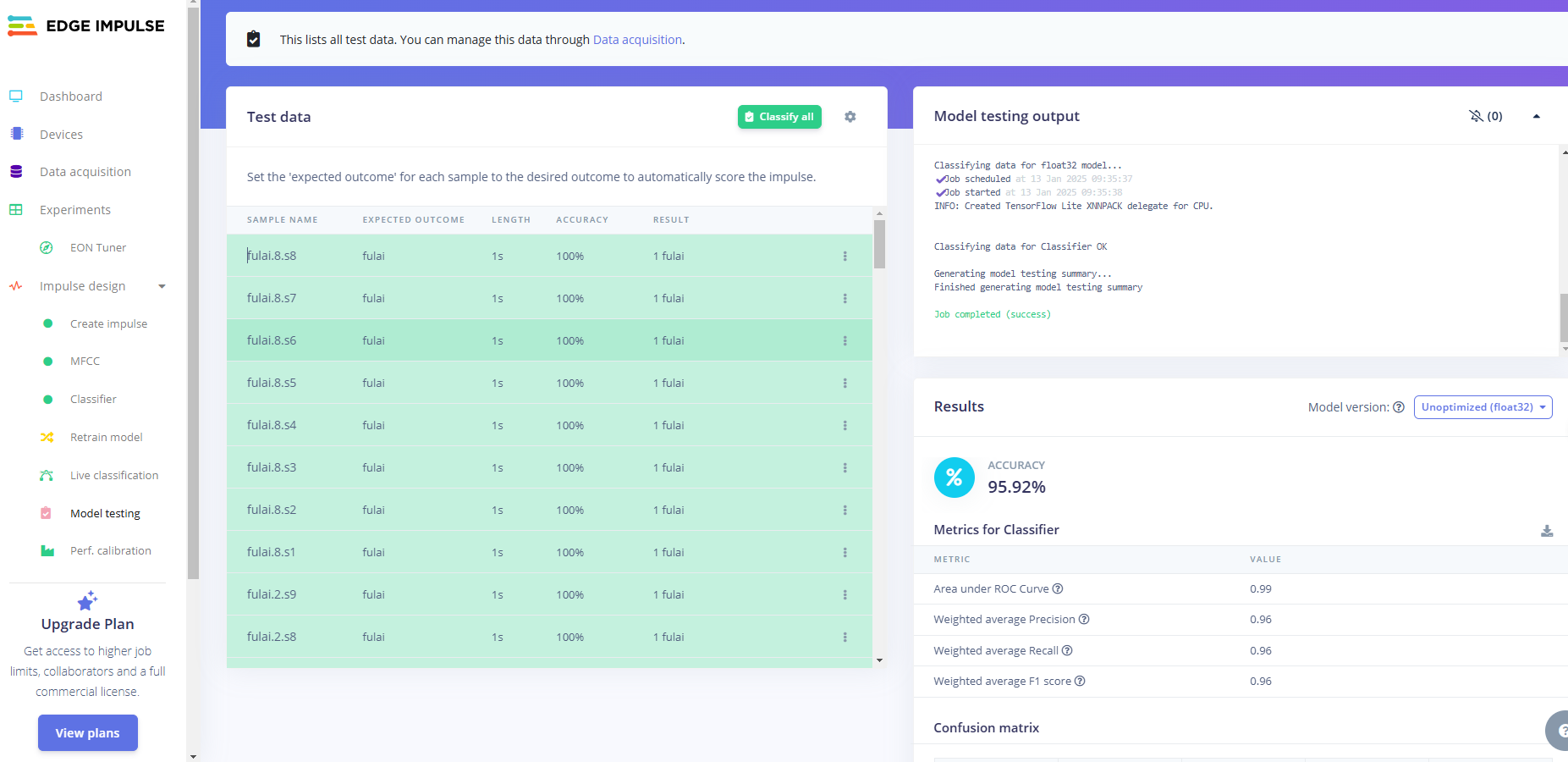
在模型训练好后,我们可以用测试集数据测试一下训练好的模型的准确率。
点击左侧的Model testing,然后点击Classify all,开始分类所有的测试集数据。
生成ESP32-S3模型库文件
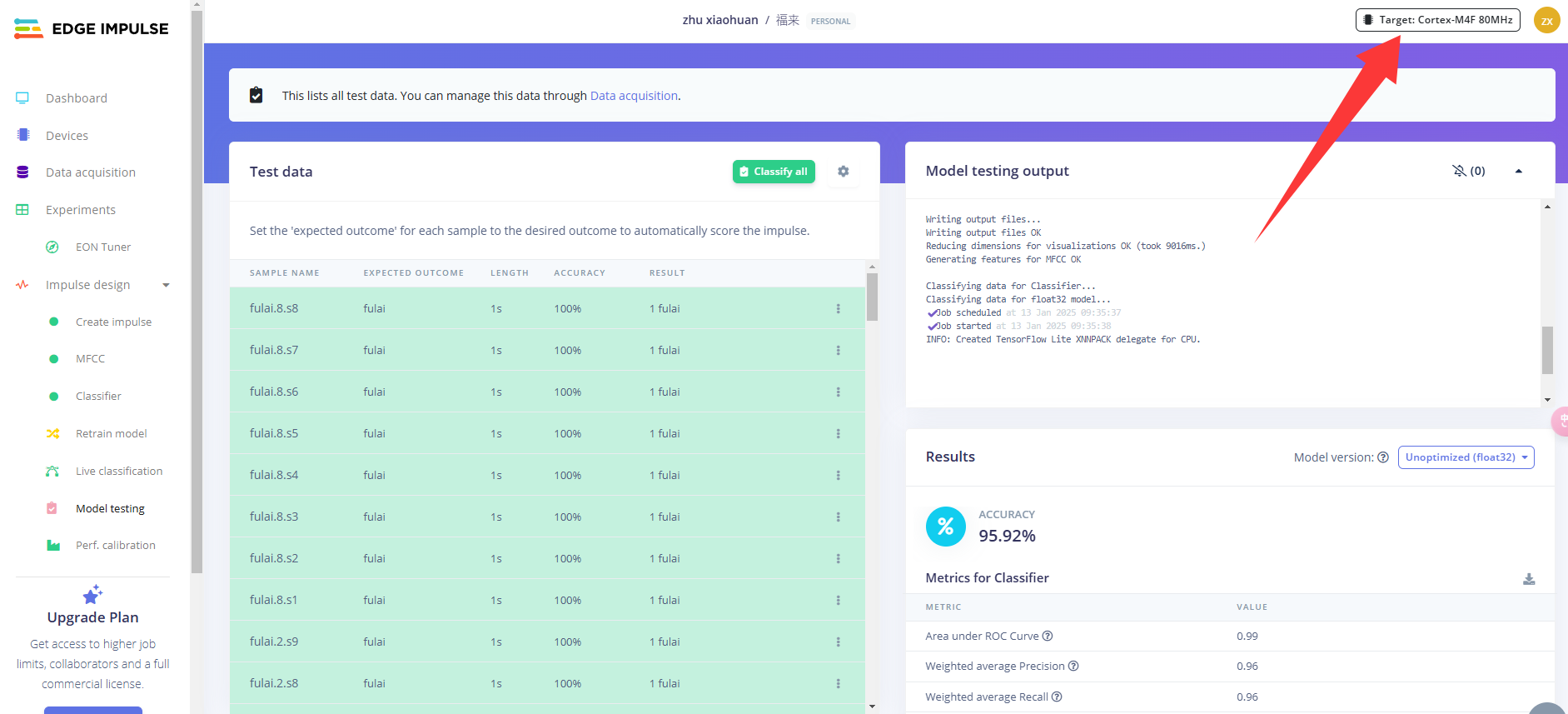
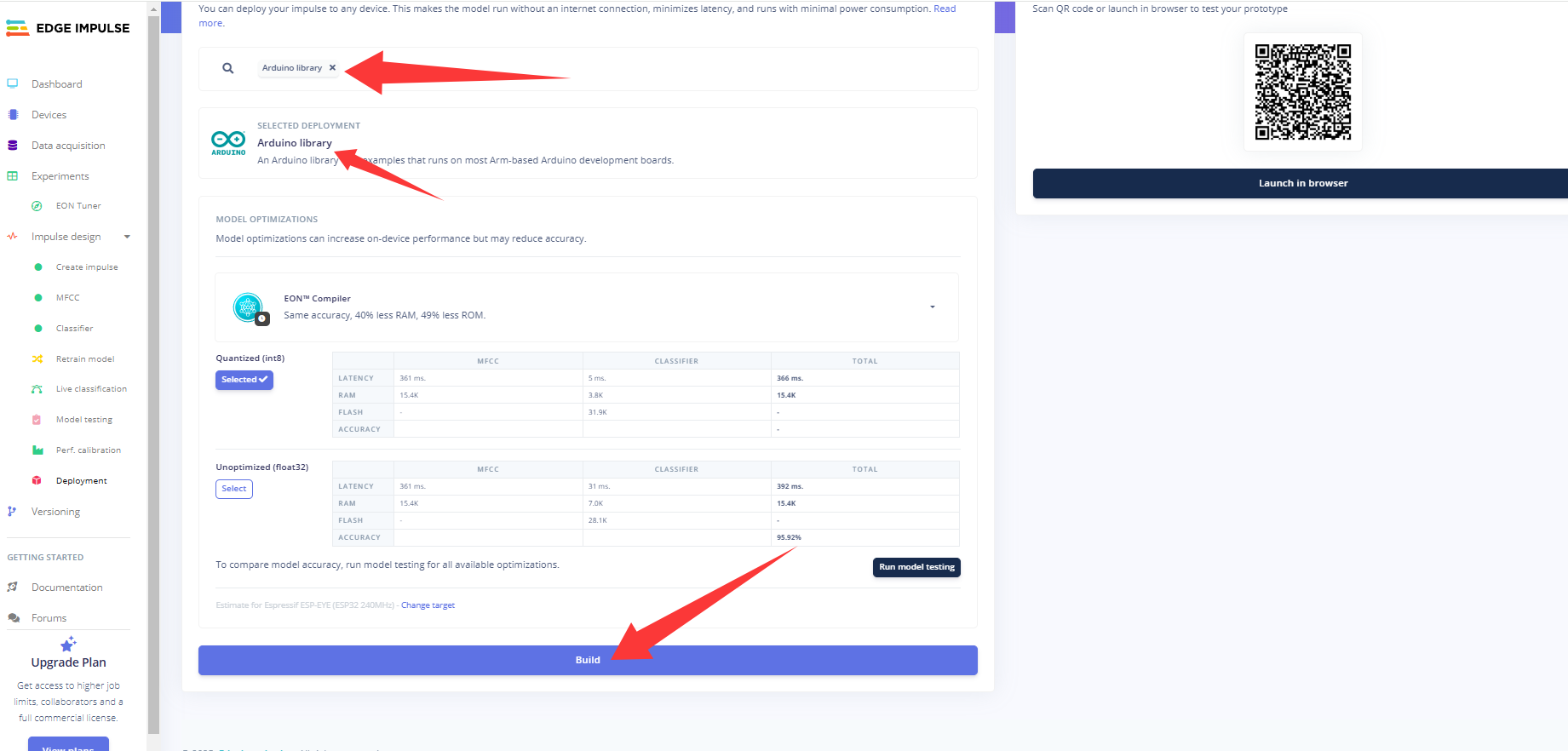
在生成库文件之前,我们先设置一下我们的硬件平台,点击右侧的 Target,选择Target device为ESP-EYE,然后点击 Save。
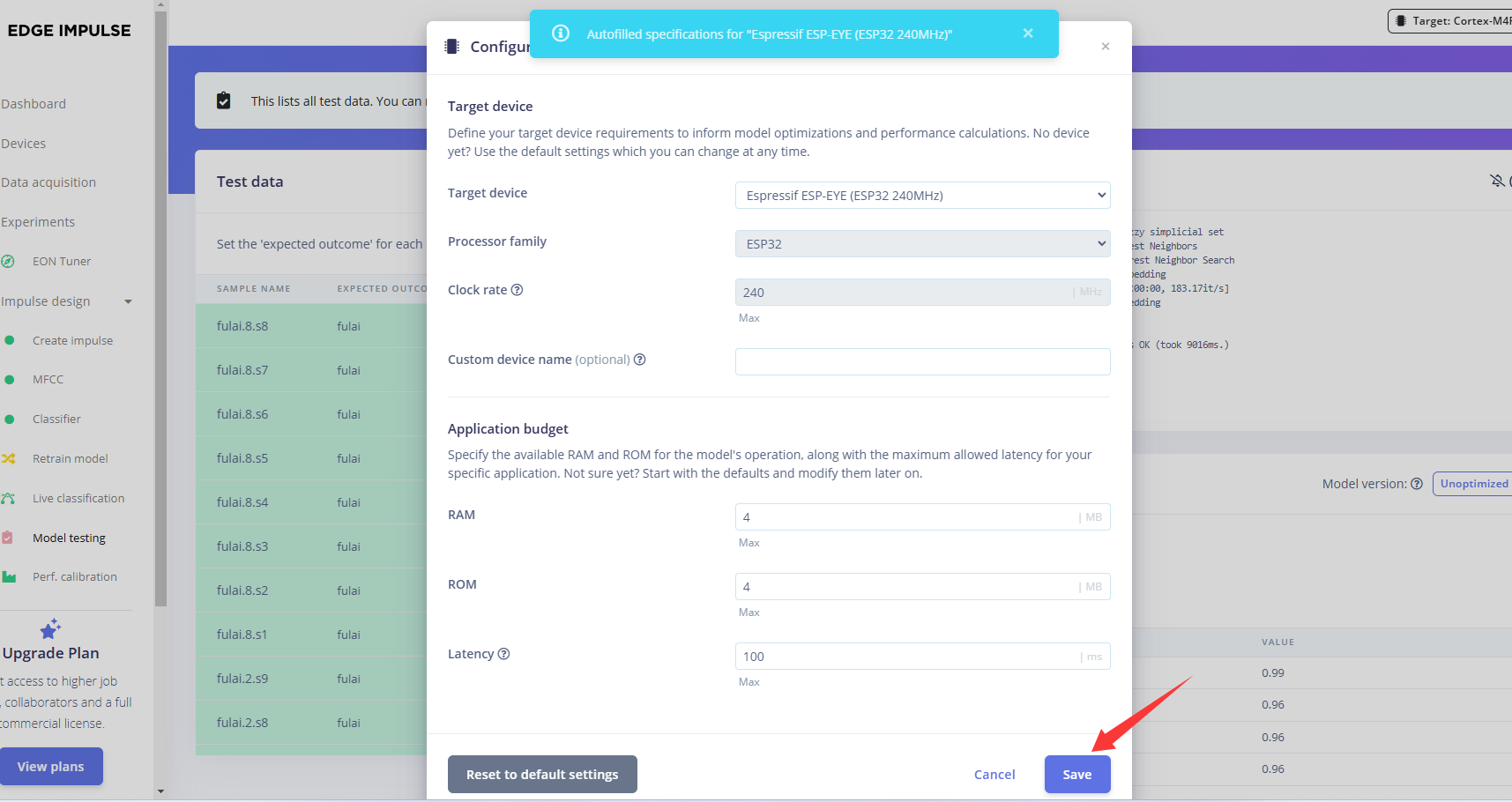
点击左侧的 Deployment部署,依次按照上图的选项配置,点击 Build,开始生成库文件。
测试唤醒
训练好唤醒词库文件后,我们需要在ESP32-S3上测试一下唤醒词功能,代码在这
/* Edge Impulse Arduino examples
* Copyright (c) 2022 EdgeImpulse Inc.
*
* Permission is hereby granted, free of charge, to any person obtaining a copy
* of this software and associated documentation files (the "Software"), to deal
* in the Software without restriction, including without limitation the rights
* to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
* copies of the Software, and to permit persons to whom the Software is
* furnished to do so, subject to the following conditions:
*
* The above copyright notice and this permission notice shall be included in
* all copies or substantial portions of the Software.
*
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
* IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
* FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
* AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
* LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
* OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
* SOFTWARE.
*/
// If your target is limited in memory remove this macro to save 10K RAM
#define EIDSP_QUANTIZE_FILTERBANK 0
/*
** NOTE: If you run into TFLite arena allocation issue.
**
** This may be due to may dynamic memory fragmentation.
** Try defining "-DEI_CLASSIFIER_ALLOCATION_STATIC" in boards.local.txt (create
** if it doesn't exist) and copy this file to
** `<ARDUINO_CORE_INSTALL_PATH>/arduino/hardware/<mbed_core>/<core_version>/`.
**
** See
** (https://support.arduino.cc/hc/en-us/articles/360012076960-Where-are-the-installed-cores-located-)
** to find where Arduino installs cores on your machine.
**
** If the problem persists then there's not enough memory for this model and application.
*/
/* Includes ---------------------------------------------------------------- */
//#include <wakeup_detect_houguotongxue_inferencing.h>
#include <driver/i2s.h>
#define SAMPLE_RATE 16000U
#define LED_BUILT_IN 21
// INMP441 config
#define I2S_IN_PORT I2S_NUM_0
#define I2S_IN_BCLK 4
#define I2S_IN_LRC 5
#define I2S_IN_DIN 6
/** Audio buffers, pointers and selectors */
typedef struct {
int16_t *buffer;
uint8_t buf_ready;
uint32_t buf_count;
uint32_t n_samples;
} inference_t;
static inference_t inference;
static const uint32_t sample_buffer_size = 2048;
static signed short sampleBuffer[sample_buffer_size];
static bool debug_nn = false; // Set this to true to see e.g. features generated from the raw signal
static bool record_status = true;
/**
* @brief Arduino setup function
*/
void setup() {
// put your setup code here, to run once:
Serial.begin(115200);
// comment out the below line to cancel the wait for USB connection (needed for native USB)
while (!Serial)
;
Serial.println("Edge Impulse Inferencing Demo");
pinMode(LED_BUILT_IN, OUTPUT); // Set the pin as output
digitalWrite(LED_BUILT_IN, HIGH); //Turn off
// Initialize I2S for audio input
i2s_config_t i2s_config_in = {
.mode = (i2s_mode_t)(I2S_MODE_MASTER | I2S_MODE_RX),
.sample_rate = SAMPLE_RATE,
.bits_per_sample = I2S_BITS_PER_SAMPLE_16BIT, // 注意:INMP441 输出 32 位数据
.channel_format = I2S_CHANNEL_FMT_ONLY_LEFT,
.communication_format = i2s_comm_format_t(I2S_COMM_FORMAT_STAND_I2S),
.intr_alloc_flags = ESP_INTR_FLAG_LEVEL1,
.dma_buf_count = 8,
.dma_buf_len = 1024,
};
i2s_pin_config_t pin_config_in = {
.bck_io_num = I2S_IN_BCLK,
.ws_io_num = I2S_IN_LRC,
.data_out_num = -1,
.data_in_num = I2S_IN_DIN
};
i2s_driver_install(I2S_IN_PORT, &i2s_config_in, 0, NULL);
i2s_set_pin(I2S_IN_PORT, &pin_config_in);
// summary of inferencing settings (from model_metadata.h)
ei_printf("Inferencing settings:\n");
ei_printf("\tInterval: ");
ei_printf_float((float)EI_CLASSIFIER_INTERVAL_MS);
ei_printf(" ms.\n");
ei_printf("\tFrame size: %d\n", EI_CLASSIFIER_DSP_INPUT_FRAME_SIZE);
ei_printf("\tSample length: %d ms.\n", EI_CLASSIFIER_RAW_SAMPLE_COUNT / 16);
ei_printf("\tNo. of classes: %d\n", sizeof(ei_classifier_inferencing_categories) / sizeof(ei_classifier_inferencing_categories[0]));
ei_printf("\nStarting continious inference in 2 seconds...\n");
ei_sleep(2000);
if (microphone_inference_start(EI_CLASSIFIER_RAW_SAMPLE_COUNT) == false) {
ei_printf("ERR: Could not allocate audio buffer (size %d), this could be due to the window length of your model\r\n", EI_CLASSIFIER_RAW_SAMPLE_COUNT);
return;
}
ei_printf("Recording...\n");
}
/**
* @brief Arduino main function. Runs the inferencing loop.
*/
void loop() {
bool m = microphone_inference_record();
if (!m) {
ei_printf("ERR: Failed to record audio...\n");
return;
}
signal_t signal;
signal.total_length = EI_CLASSIFIER_RAW_SAMPLE_COUNT;
signal.get_data = µphone_audio_signal_get_data;
ei_impulse_result_t result = { 0 };
EI_IMPULSE_ERROR r = run_classifier(&signal, &result, debug_nn);
if (r != EI_IMPULSE_OK) {
ei_printf("ERR: Failed to run classifier (%d)\n", r);
return;
}
int pred_index = 0; // Initialize pred_index
float pred_value = 0; // Initialize pred_value
// print the predictions
ei_printf("Predictions ");
ei_printf("(DSP: %d ms., Classification: %d ms., Anomaly: %d ms.)",
result.timing.dsp, result.timing.classification, result.timing.anomaly);
ei_printf(": \n");
for (size_t ix = 0; ix < EI_CLASSIFIER_LABEL_COUNT; ix++) {
ei_printf(" %s: ", result.classification[ix].label);
ei_printf_float(result.classification[ix].value);
ei_printf("\n");
if (result.classification[ix].value > pred_value) {
pred_index = ix;
pred_value = result.classification[ix].value;
}
}
// Display inference result
if (pred_index == 3) {
digitalWrite(LED_BUILT_IN, LOW); //Turn on
} else {
digitalWrite(LED_BUILT_IN, HIGH); //Turn off
}
#if EI_CLASSIFIER_HAS_ANOMALY == 1
ei_printf(" anomaly score: ");
ei_printf_float(result.anomaly);
ei_printf("\n");
#endif
}
static void audio_inference_callback(uint32_t n_bytes) {
for (int i = 0; i < n_bytes >> 1; i++) {
inference.buffer[inference.buf_count++] = sampleBuffer[i];
if (inference.buf_count >= inference.n_samples) {
inference.buf_count = 0;
inference.buf_ready = 1;
}
}
}
static void capture_samples(void *arg) {
const int32_t i2s_bytes_to_read = (uint32_t)arg;
size_t bytes_read = i2s_bytes_to_read;
while (record_status) {
/* read data at once from i2s - Modified for XIAO ESP2S3 Sense and I2S.h library */
i2s_read(I2S_IN_PORT, (void*)sampleBuffer, i2s_bytes_to_read, &bytes_read, 100);
// esp_i2s::i2s_read(esp_i2s::I2S_NUM_0, (void *)sampleBuffer, i2s_bytes_to_read, &bytes_read, 100);
if (bytes_read <= 0) {
ei_printf("Error in I2S read : %d", bytes_read);
} else {
if (bytes_read < i2s_bytes_to_read) {
ei_printf("Partial I2S read");
}
// scale the data (otherwise the sound is too quiet)
for (int x = 0; x < i2s_bytes_to_read / 2; x++) {
sampleBuffer[x] = (int16_t)(sampleBuffer[x]) * 8;
}
if (record_status) {
audio_inference_callback(i2s_bytes_to_read);
} else {
break;
}
}
}
vTaskDelete(NULL);
}
/**
* @brief Init inferencing struct and setup/start PDM
*
* @param[in] n_samples The n samples
*
* @return { description_of_the_return_value }
*/
static bool microphone_inference_start(uint32_t n_samples) {
inference.buffer = (int16_t *)malloc(n_samples * sizeof(int16_t));
if (inference.buffer == NULL) {
return false;
}
inference.buf_count = 0;
inference.n_samples = n_samples;
inference.buf_ready = 0;
// if (i2s_init(EI_CLASSIFIER_FREQUENCY)) {
// ei_printf("Failed to start I2S!");
// }
ei_sleep(100);
record_status = true;
xTaskCreate(capture_samples, "CaptureSamples", 1024 * 32, (void *)sample_buffer_size, 10, NULL);
return true;
}
/**
* @brief Wait on new data
*
* @return True when finished
*/
static bool microphone_inference_record(void) {
bool ret = true;
while (inference.buf_ready == 0) {
delay(10);
}
inference.buf_ready = 0;
return ret;
}
/**
* Get raw audio signal data
*/
static int microphone_audio_signal_get_data(size_t offset, size_t length, float *out_ptr) {
numpy::int16_to_float(&inference.buffer[offset], out_ptr, length);
return 0;
}
/**
* @brief Stop PDM and release buffers
*/
static void microphone_inference_end(void) {
free(sampleBuffer);
ei_free(inference.buffer);
}
#if !defined(EI_CLASSIFIER_SENSOR) || EI_CLASSIFIER_SENSOR != EI_CLASSIFIER_SENSOR_MICROPHONE
#error "Invalid model for current sensor."
#endif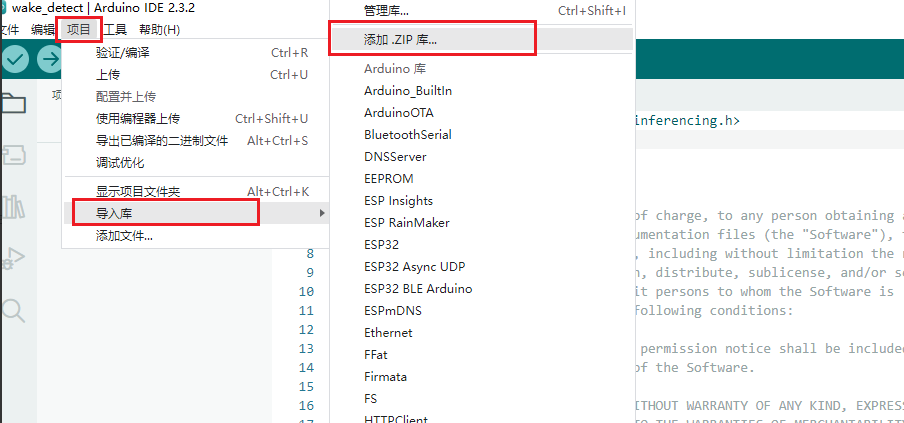
导入成功后,我们需要引用该库文件,因此再次点击项目,导入库,点击选择刚才导入的库文件。
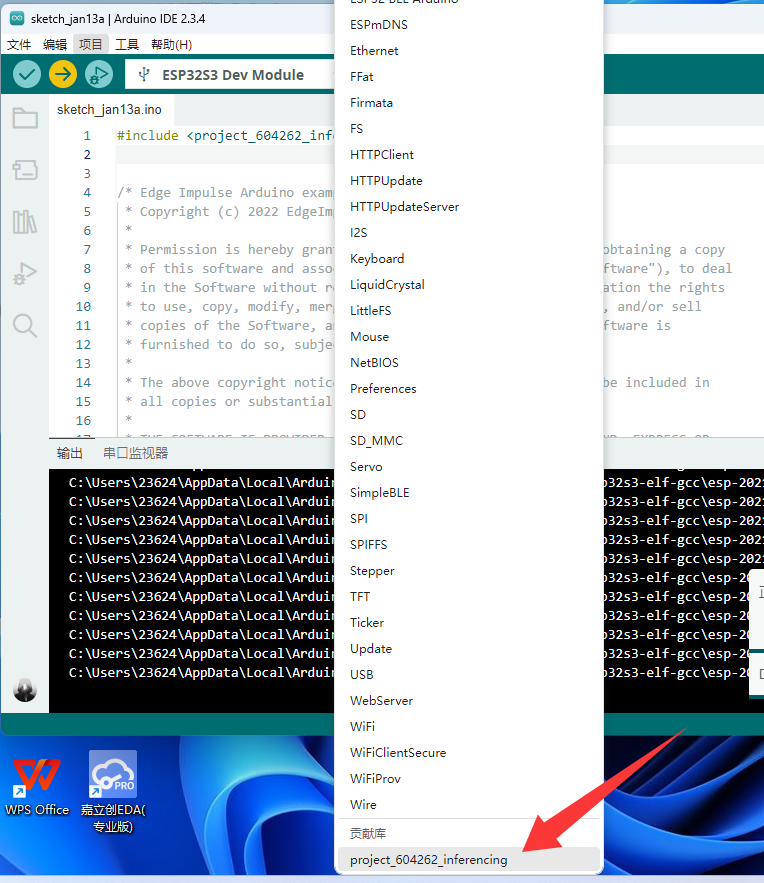
编译就好了
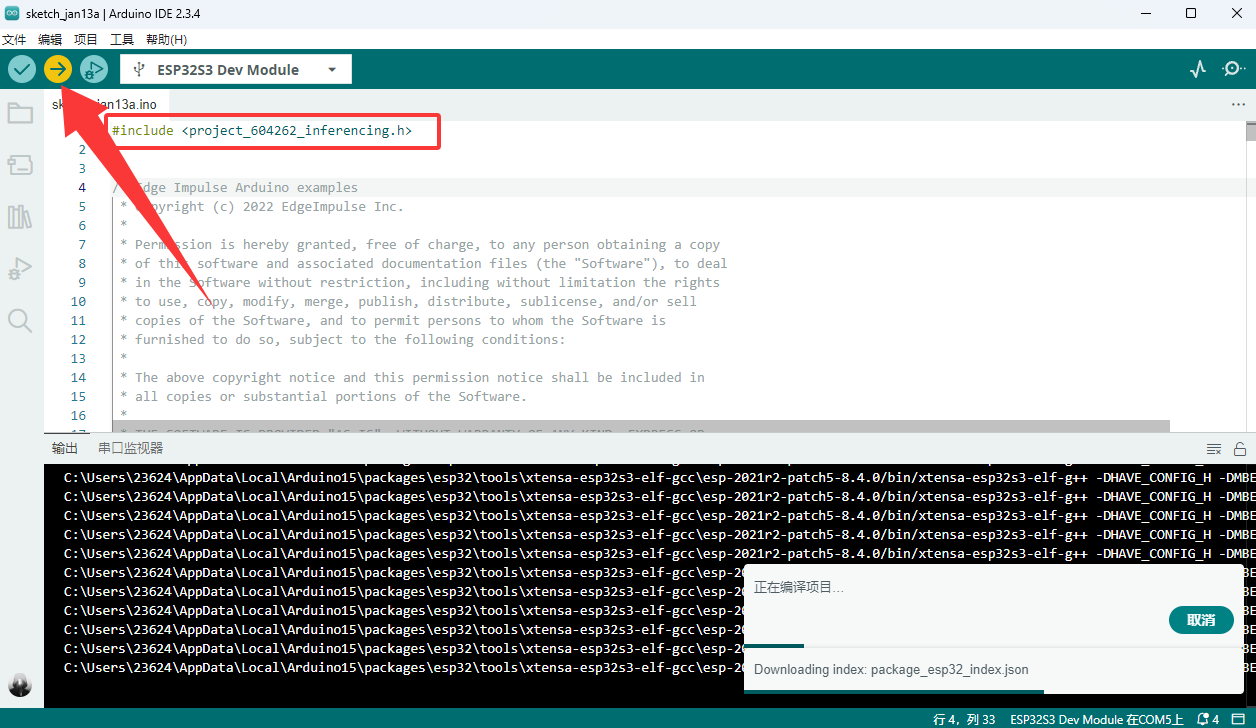
然后唤醒词唤醒,值接近1,说明唤醒成功了
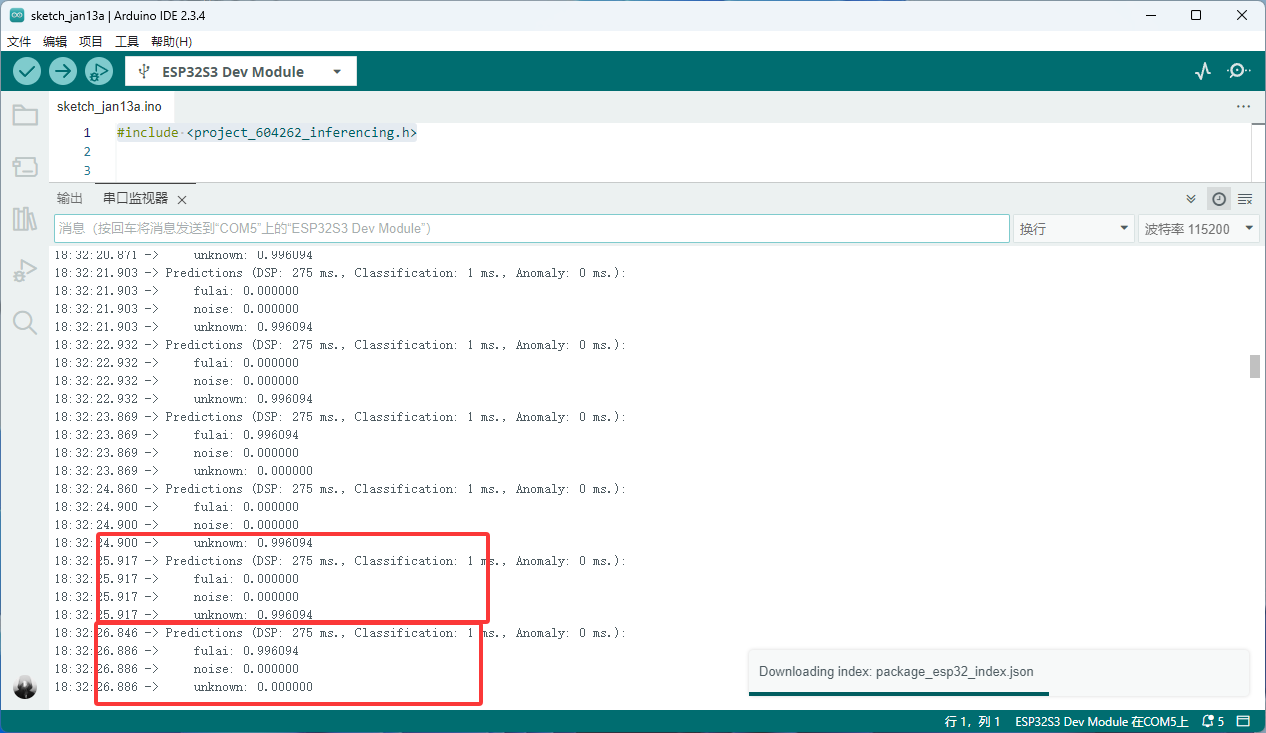
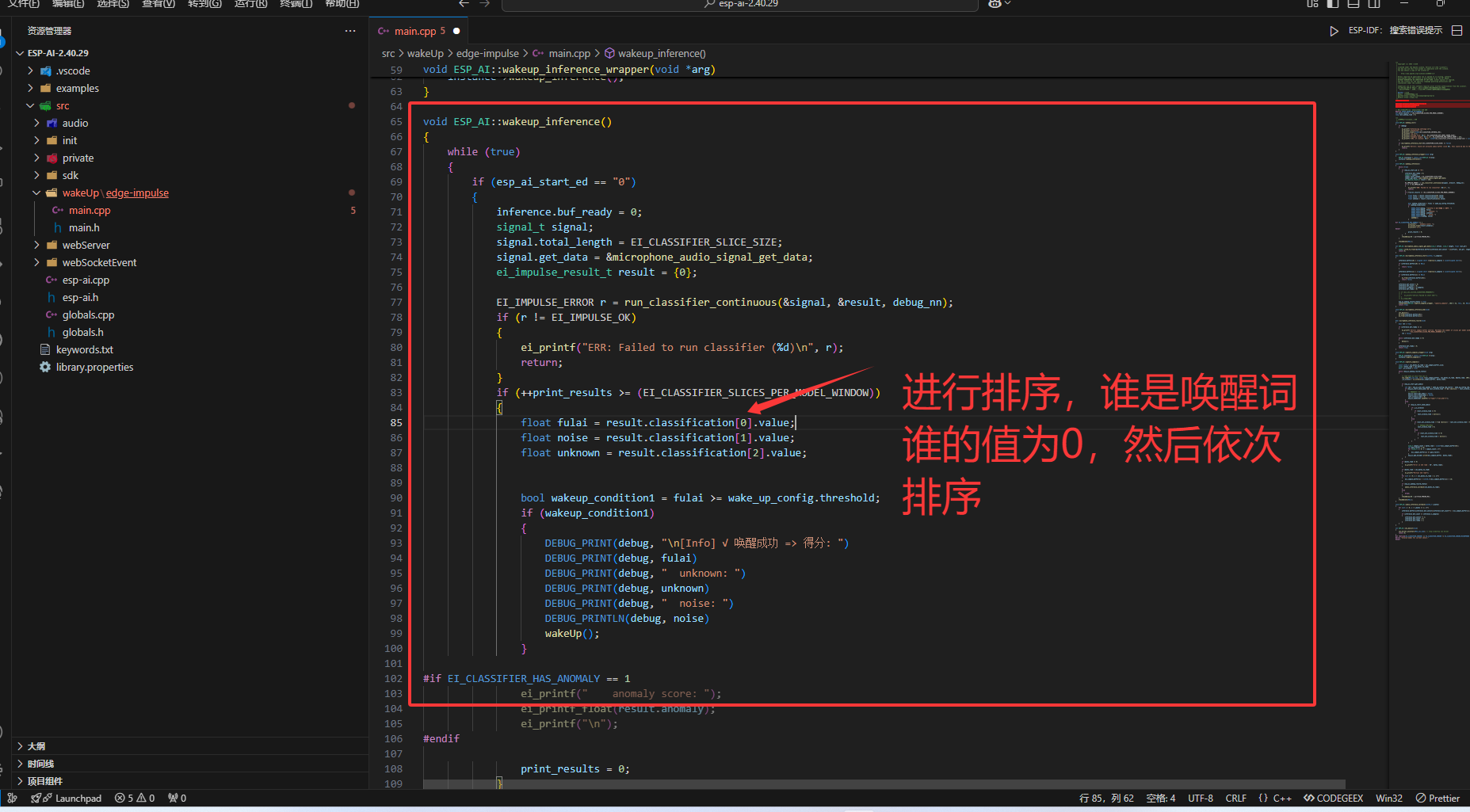
ESP-AI替换唤醒词
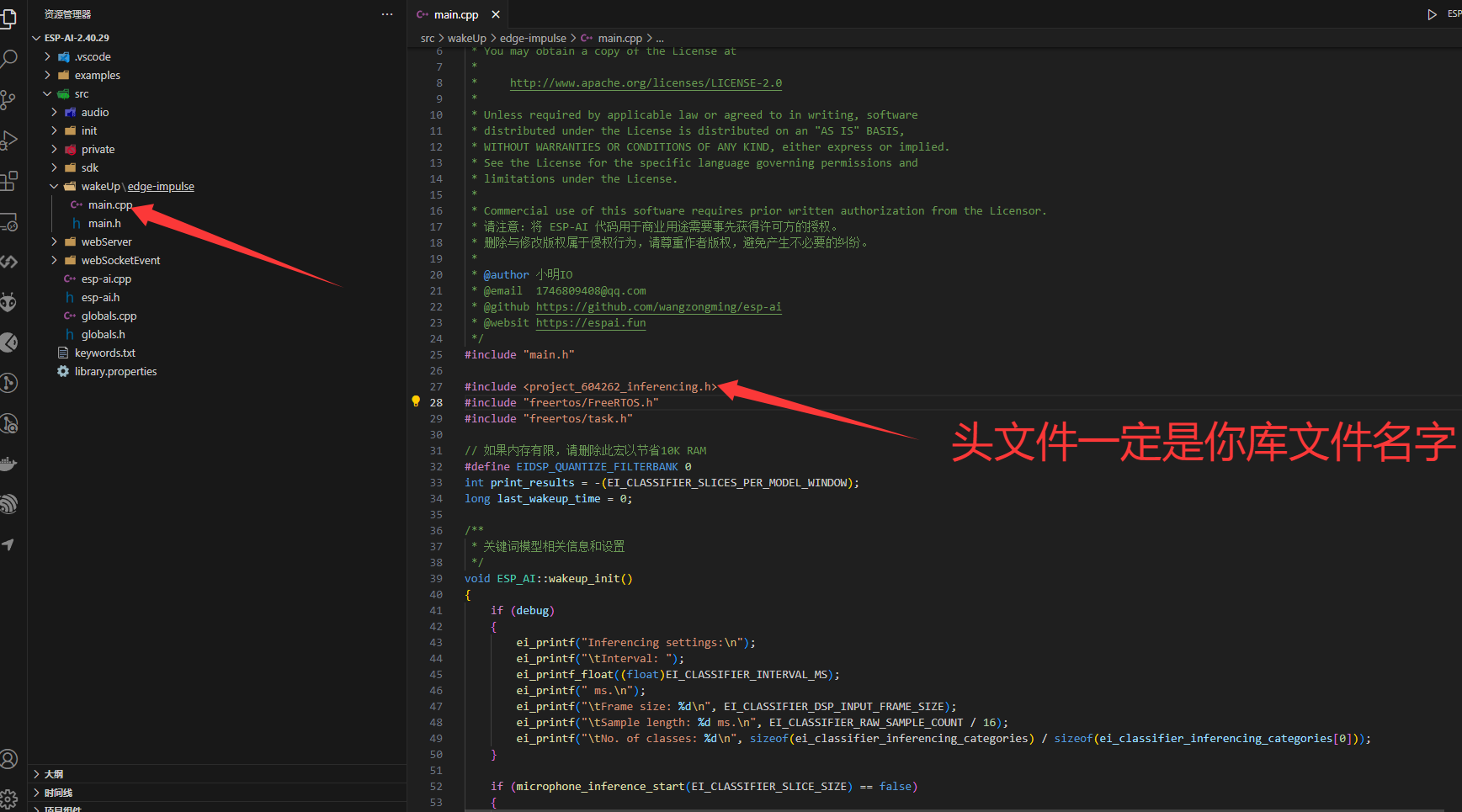
将xmtx替换成fulai
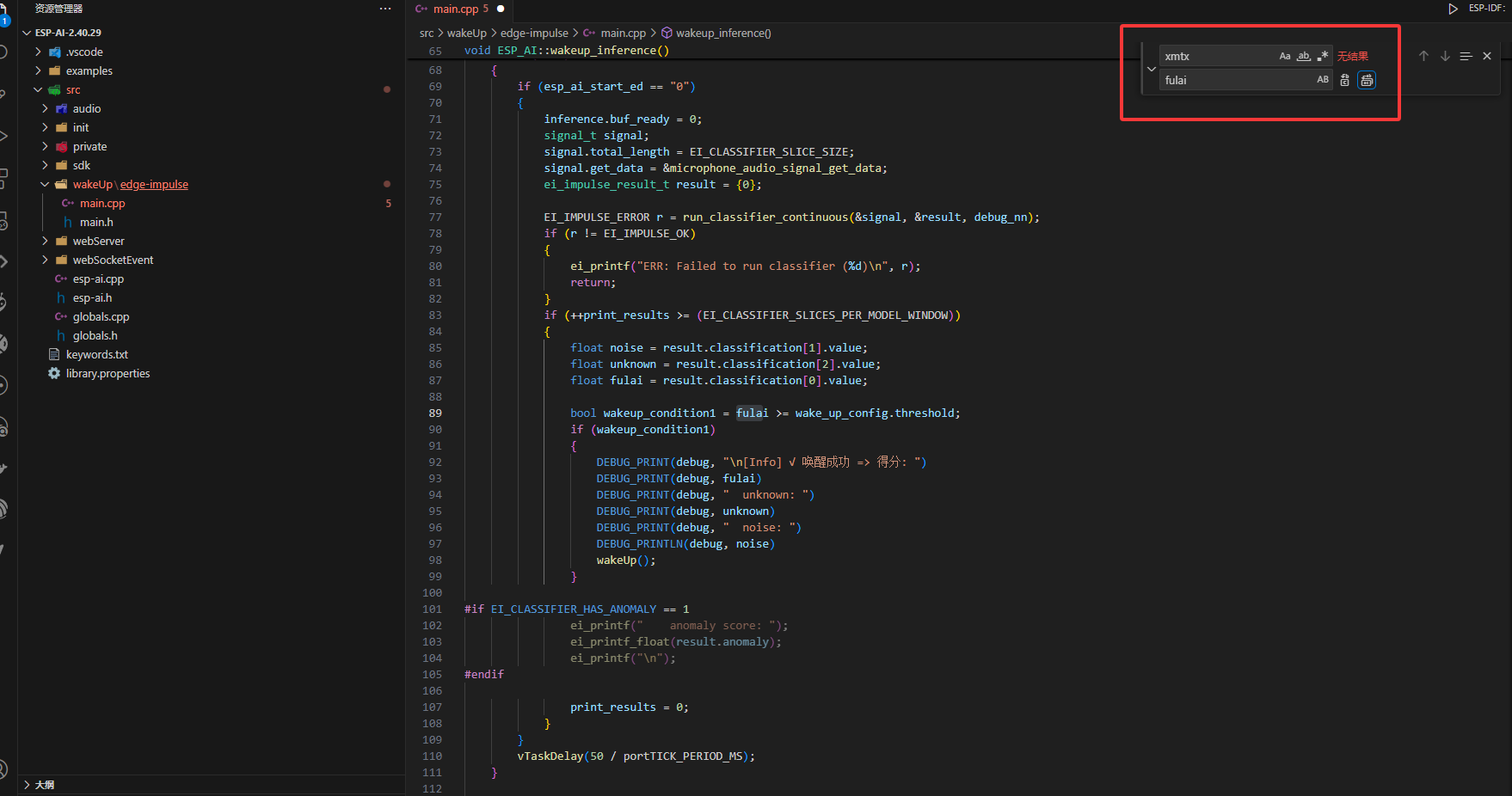
串口输出查看这三个顺序
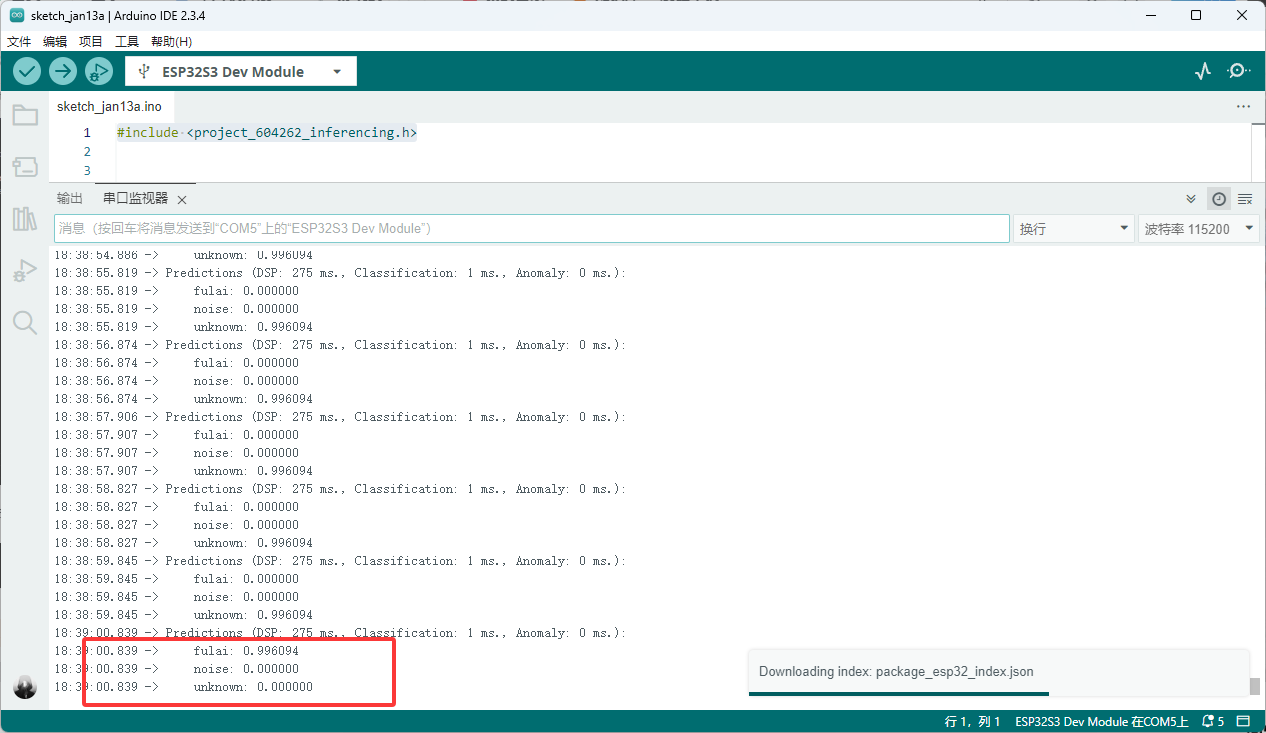
进行排序,最后编译即可
















- 最新
- 最热
只看作者