


开发背景
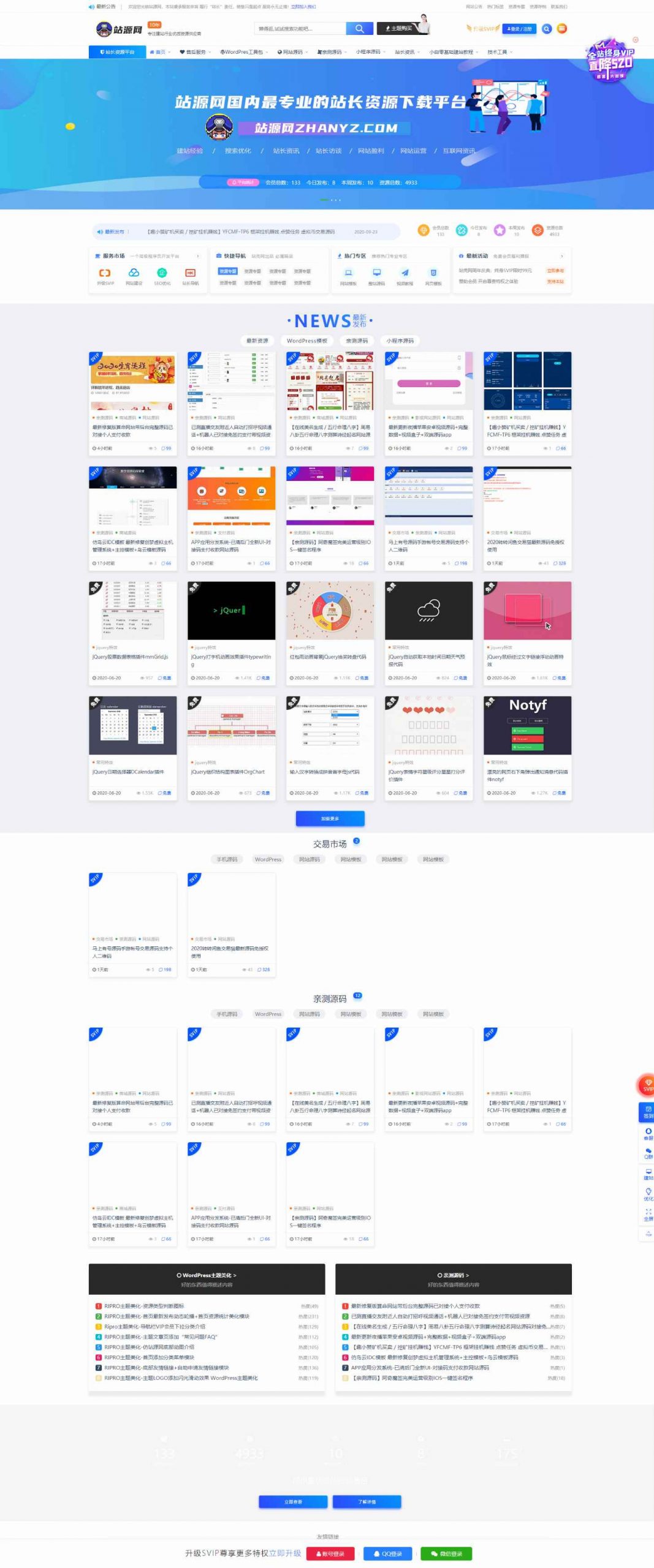
我们在做网站的时候总是会遇到自己喜欢的网站,但是模板在别人手上,站长一般是不会给你的,除非你掏钱他才会给你,这样对我们的钱包很不友好,所以我写了这个爬站助手,准确率能达到90%,非常的好用!
| 名称 | 内容 |
|---|---|
| 开发语言 | |
| 开发工具 | pycharm |
| 使用模块 | requests,requests,os |
| 爬取内容 | html,js,css |
| 弊端 | 暂不支持爬取图片(懒得写,后面有需要再写吧) |
| 使用方法 | 第一个值输入要扒的站点,第二个值输入要扒的页面,回车运行 |
代码
import requests
import re
import os
wangzhan=input('请输入你要爬取的网站:')
url=input('请输入你要爬取的页面:')
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0.1; Moto G (4)) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Mobile Safari/537.36 Edg/87.0.664.47'}
josn_1 = requests.get(url)
conten = josn_1.text
# print(conten)
f1 = open('index.html', 'w',encoding='utf-8')
f1.write(conten)
f1.close()
n = re.findall(r'href="/(.+?)s"', conten) # js css正则表达式匹配
n2 = re.findall(r'href="/(.+?)jpg"', conten) # 图片 正则表达式匹配
n3 = re.findall(r'href="/(.+?)png"', conten) # 图片 正则表达式匹配
def js():
for css in n:
aa = wangzhan + css + 's'
cssjs = css + 's'
# print(cssjs)
link = wangzhan + '/' + cssjs
# print(link)
a = '/'
list = []
for name in cssjs:
list.append(name)
b = '/'
try:
c = ([i for i, x in enumerate(list) if x == b])
l = int(c[-1])
except:
print('跳过')
# print(c)
for name2 in c:
path1 = cssjs[0:l]
# print(path1)
isExists = os.path.exists(path1)
# 判断结果
if not isExists:
os.makedirs(path1)
msg = requests.get(link).text
print('正在抓取')
f = open(cssjs, 'w', encoding='utf-8')
f.write(msg)
f.close()
print('爬取完成')
def img():
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0.1; Moto G (4)) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Mobile Safari/537.36 Edg/87.0.664.47'}
josn_1 = requests.get(url)
conten = josn_1.text
# print(conten)
f1 = open('index.html', 'w', encoding='utf-8')
f1.write(conten)
f1.close()
n = re.findall(r'href="/(.+?)s"', conten) # js css正则表达式匹配
n2 = re.findall(r'src="/(.+?)jpg"', conten) # 图片 正则表达式匹配
n3 = re.findall(r'src="/(.+?)png"', conten) # 图片 正则表达式匹配
# png
for png in n3:
a = '/'
list = []
for name in png:
list.append(name)
# print(png)
b = '/'
c = ([i for i, x in enumerate(list) if x == b])
l = int(c[-1])
# print(l)
for name2 in c:
# print(name2)
png_url = url + png[0:-1] + '.png' # 图片网址
aa = c[-1]
bb = png[l + 1:-1] + '.png'
png_path = png[0:l] # 路径
png_path1 = os.getcwd() + '/' + png_path + '/' + bb # 路径
print(png_path1)
isExists = os.path.exists(png_path)
# 判断结果
if not isExists:
os.makedirs(png_path)
else:
msg = requests.get(png_url, stream=True)
with open(png_path1, 'wb') as fd:
for chunk in msg.iter_content():
fd.write(chunk)
print('ok')
# jpg
for png in n2:
a = '/'
list = []
for name in png:
list.append(name)
# print(png)
b = '/'
c = ([i for i, x in enumerate(list) if x == b])
l = int(c[-1])
# print(l)
for name2 in c:
# print(name2)
png_url = url + png[0:-1] + '.png' # 图片网址
aa = c[-1]
bb = png[l + 1:-1] + '.png'
png_path = png[0:l] # 路径
png_path1 = os.getcwd() + '/' + png_path + '/' + bb # 路径
print(png_path1)
isExists = os.path.exists(png_path)
# 判断结果
if not isExists:
os.makedirs(png_path)
else:
msg = requests.get(png_url, stream=True)
with open(png_path1, 'wb') as fd:
for chunk in msg.iter_content():
fd.write(chunk)
print('ok')
if __name__ == '__main__':
js()
img()
© 版权声明
THE END











暂无评论内容